

July 14, 2025
AWS Launches EC2 UltraServers Powered by NVIDIA Grace Blackwell
July 14, 2025 — Amazon Web Services (AWS) has announced the general availability of Amazon Elastic Compute Cloud (Amazon EC2) P6e-GB200 UltraServers, accelerated by NVIDIA GB200 NVL72 to offer the highest GPU performance for AI training and inference. Amazon EC2 UltraServers connect multiple EC2 instances using a dedicated, high-bandwidth, and low-latency accelerator interconnect across these instances.
 The NVIDIA Grace Blackwell Superchips connect two high-performance NVIDIA Blackwell tensor core GPUs and an NVIDIA Grace CPU based on Arm architecture using the NVIDIA NVLink-C2C interconnect. Each Grace Blackwell Superchip delivers 10 petaflops of FP8 compute (without sparsity) and up to 372 GB HBM3e memory. With the superchip architecture, GPU and CPU are colocated within one compute module, increasing bandwidth between GPU and CPU significantly compared to current generation EC2 P5en instances.
The NVIDIA Grace Blackwell Superchips connect two high-performance NVIDIA Blackwell tensor core GPUs and an NVIDIA Grace CPU based on Arm architecture using the NVIDIA NVLink-C2C interconnect. Each Grace Blackwell Superchip delivers 10 petaflops of FP8 compute (without sparsity) and up to 372 GB HBM3e memory. With the superchip architecture, GPU and CPU are colocated within one compute module, increasing bandwidth between GPU and CPU significantly compared to current generation EC2 P5en instances.
With EC2 P6e-GB200 UltraServers, users can access up to 72 NVIDIA Blackwell GPUs within one NVLink domain to use 360 petaflops of FP8 compute (without sparsity) and 13.4 TB of total high bandwidth memory (HBM3e). Powered by the AWS Nitro System, P6e-GB200 UltraServers are deployed in EC2 UltraClusters to securely and reliably scale to tens of thousands of GPUs.
EC2 P6e-GB200 UltraServers deliver up to 28.8 Tbps of total Elastic Fabric Adapter (EFAv4) networking. EFA is also coupled with NVIDIA GPUDirect RDMA to enable low-latency GPU-to-GPU communication between servers with operating system bypass.
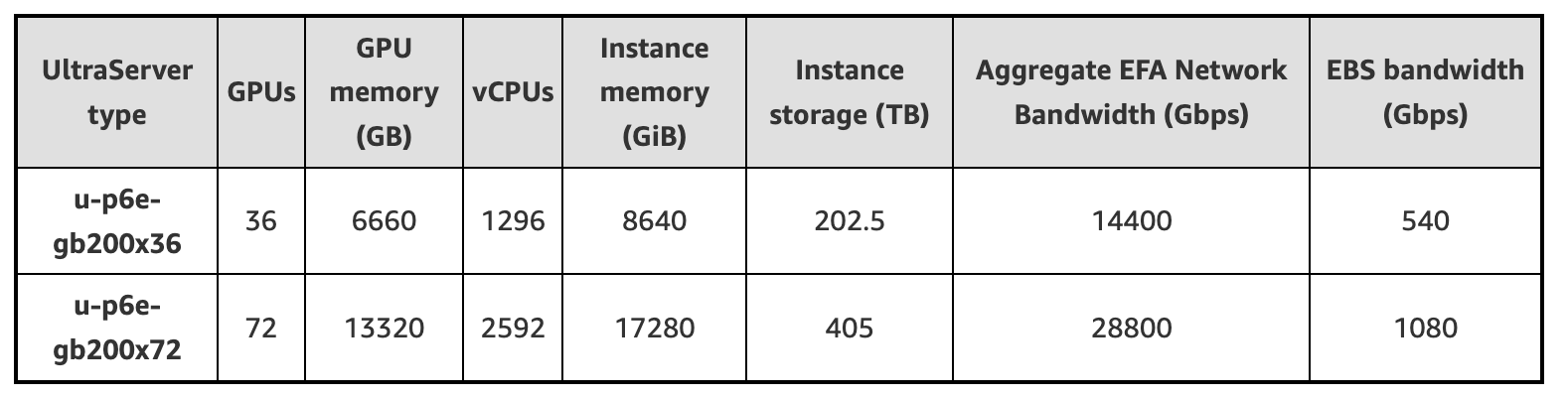
EC2 P6e-GB200 UltraServers Specifications
EC2 P6e-GB200 UltraServers are available in sizes ranging from 36 to 72 GPUs under NVLink. Here are the specs for EC2 P6e-GB200 UltraServers:
P6e-GB200 UltraServers are ideal for the most compute and memory intensive AI workloads, such as training and inference of frontier models, including mixture of experts models and reasoning models, at the trillion-parameter scale.
EC2 P6e-GB200 UltraServers can be integrated seamlessly with various AWS managed services. For example:
- Amazon SageMaker Hyperpod provides managed, resilient infrastructure that automatically handles the provisioning and management of P6e-GB200 UltraServers, replacing faulty instances with preconfigured spare capacity within the same NVLink domain to maintain performance.
- Amazon Elastic Kubernetes Services (Amazon EKS) allows one managed node group to span across multiple P6e-GB200 UltraServers as nodes, automating their provisioning and lifecycle management within Kubernetes clusters. You can use EKS topology-aware routing for P6e-GB200 UltraServers, enabling optimal placement of tightly coupled components of distributed workloads within a single UltraServer’s NVLink-connected instances.
- Amazon FSx for Lustre file systems provide data access for P6e-GB200 UltraServers at the hundreds of GB/s of throughput and millions of input/output operations per second (IOPS) required for large-scale HPC and AI workloads. For fast access to large datasets, you can use up to 405 TB of local NVMe SSD storage or virtually unlimited cost-effective storage with Amazon Simple Storage Service (Amazon S3).
Now Available
Amazon EC2 P6e-GB200 UltraServers are now available in the Dallas Local Zone through EC2 Capacity Blocks for ML. For more information, visit the Amazon EC2 pricing page.
Try Amazon EC2 P6e-GB200 UltraServers in the Amazon EC2 console. To learn more, visit the Amazon EC2 P6e instances page and send feedback to AWS re:Post for EC2 or through AWS Support contacts.
Source: Channy Yun, AWS
Leading Solution Providers









Tabor Network
















