


July 17, 2014
Inside Sibyl, Google’s Massively Parallel Machine Learning Platform
If you’ve ever wondered how your spam gets identified in Gmail or where personal video recommendations come from on YouTube, the answer is likely Sibyl, a massively parallel machine learning system that Google developed to make predictions and recommendations with user-specific data culled from its Internet applications.
Dr. Tushar Chandra, a distinguished Google Research engineer, recently shared some information on Sibyl in a keynote presentation at the annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). Sibyl is not the only machine learning platform in use at the Web giant, but the “embarrassingly parallel,” supervised system named after the mystical Greek prognosticator certainly has become a prominent tool for predicting how Google users will behave in the future based on what they did in the past.
According to Chandra, Google started developing Sibyl several years ago for the purpose of generating YouTube video recommendations. The machine learning platform worked so well that, pretty soon, more people were choosing what to watch based on the “recommended videos” list that appear on the right-hand side of the screen than other ways of picking videos, such as Web searches or email referrals from friends. For Chandra’s young son, it was the only way he could navigate the site to watch his favorite “Thomas the Tank Engine” videos.
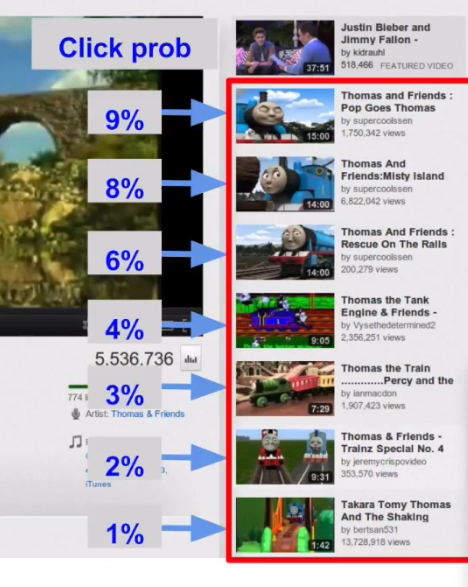
Google uses Sibyl to generate click-rate probabilities for Thomas the Tank Engine videos.
It didn’t take a leap of imagination to show that this type of machine learning technology could have application in the wider Google-sphere. “We’ve been working on Sibyl for several years now and have had a number of successes,” he says. “We use it in monetization to improve the quality of ads. We use it to detect spam and bad content showing up in email and other sources. And in fact we can use it in many, many other settings as well, and we have done so.”
It’s clear that Sibyl has become one of Google’s go-to machine learning platforms. The success of the system is a reflection of how it was built. According to Chandra, there were several design parameters that Google wanted to meet with the machine learning platform.
For starters, it needed to scale. Google has hundreds of millions (if not billions) of users around the planet, and remembers (via extensive logging) what screens it shows them and what they did on those screens. For each application, there could be hundreds of different features that needed to be tracked. The machine learning platform had to be capable of working on these massive data sets to generate useful predictions.
“A large property can have hundreds of billions of training examples,” he says. “What do I mean by a training example? It’s a single user experience. On YouTube, perhaps it’s that one [Thomas the Tank Engine] webpage my son saw six months ago, along with all the recommendations that we showed him. We also record the outcome to know whether the recommendations we made are good or whether they’re bad. That’s a single training exercise. On a large property, you can easily get into hundreds of billions of these.”

Tushar Chandra is Principal Engineer at Google Research and a co-lead for the Sibyl project. He received his Ph.D. in Computer Science from Cornell University in 1993, worked at IBM Research thereafter until he joined Google in 2004.
Secondly, Google wanted to use standard software components wherever possible. That’s where MapReduce and the distributed Google File System (GFS) come into play.
“I have seen multiple designs for large-scale machine learning,” Chandra says. “To the best of my knowledge, Sibyl is the only system that did not build its own distributed system. Every other system has a custom distributed system built inside. This is done by design. We really did not want to build a distributed system in order to build machine learning system. Of course we use MapReduce and GFS to give us what need for a distributed system.”
On top of this base of MapReduce and GFS, Google applied the Parallel Boosting Algorithm developed in 2001 by Michael Collins, Robert E. Schapire, and Yoram Singer. “We use algorithms that have been well proven in the literature,” Chandra says. “Parallel boosting is particularly well-suited for some of our requirements.”
With parallel boosting, models are guaranteed to get better over time. “We start with an approximate solution and approximate model,” Chandra says. “That model could be really bad…Then we feed the model and all the training data in…At the end of the iteration, the algorithm is guaranteed to produce a better model. So if you keep iterating, the model gets better and better and better.”
There’s another design element that went into the machine learning platform and how it handles log files and metadata. On YouTube, it turns out that people are much more likely to watch a video if it’s published by a reputable company like Sony “than if it was a video published by me,” says Chandra, “which is going to be shaky and awful quality and perhaps irrelevant to everybody else.”
Google keeps track of information like “publishers” using metadata stored in a separate database table, thereby enabling Sibyl to pull the relevant data during model runs. However, pulling this metadata creates a possible bottleneck in the analytic pipeline. “If you’re going to record all the information, our compression logs become very, very large and that becomes pretty expensive,” Chandra says. “So instead what we did is we normalized the logs and in many cases we just record the ID of the document that we’re showing in our logs, then we join it with database table that we normalized.”

Sibyl is an old woman in Greek mythology known for uttering predictions in ecstatic frenzy.
For this, Google uses a column-oriented database, which it found is faster and much better suited than a row-oriented database. The relevant data (one feature per column) can be pulled into the machine learning models much quicker in a column-oriented DB compared to the numerous row-scans required in a traditional database, and the data transformations also consume fewer resources. The column-oriented database also speeds data compression.
Sibyl runs quite well on Google’s high-RAM, multi-core servers. The system is running constantly, day and night, iterating until the figurative cows converge on the barn. It takes roughly 10 to 50 cycles to generate a recommendation that Google is happy with.
Google’s internal users are also pleased with the performance of the Sibyl cluster, according to Chandra. And while there’s no indication that Google is going to share Sibyl via open source, there’s nothing stopping others from assembling their own Sibyls using the open source components that went into the machine learning platform, or using other commonly available machine learning packages.
“We’ve used these kinds of services on multiple properties to solve multiple types of problems,” Chandra says. “This strongly suggests that there is value in having a large scale machine learning platform, rather than having one-off solutions for every new problem that occurred.
Related Items:
Google Re-Imagines MapReduce, Launches DataFlow
Google Bypasses HDFS with New Cloud Storage Option
Thinking in 10x and Other Google Directives
Leading Solution Providers
















