

August 23, 2023
Zoom Data Debacle Shines Light on SaaS Data Snooping

(Ken Cook/Shutterstock)
Zoom upset customers when it failed to properly inform them it was using audio, video, and transcripts of calls to train its AI models. Are similar data pitfalls lurking for other software providers?
Zoom was forced into damage control mode earlier this month after customers became outraged that the company was harvesting their data without their knowledge. The uproar started on August 6, when Stack Diary published a story about the lack of consent for data collection in Zoom’s terms and conditions.
After a couple false starts, Zoom changed its terms to clearly state that it “does not use any of your audio, video, chat, screen sharing, attachments or other communications…to train Zoom or third-party artificial intelligence models.”
While your friendly neighborhood video call app may have backed down from its ambitious data harvesting and AI training project, it begs the question: What other software companies or software as a service (SaaS) providers are doing something similar?
SaaS Data Growth
Companies like Salesforce, NetSuite, and ServiceNow grew their fledgling SaaS offerings for CRM, ERP, and service desk software into massive businesses generating billions of dollars from tens of thousands of companies. Microsoft, Oracle, SAP, and other enterprise software vendors followed suit, and today average company uses 130 different SaaS tools, according to Statista.
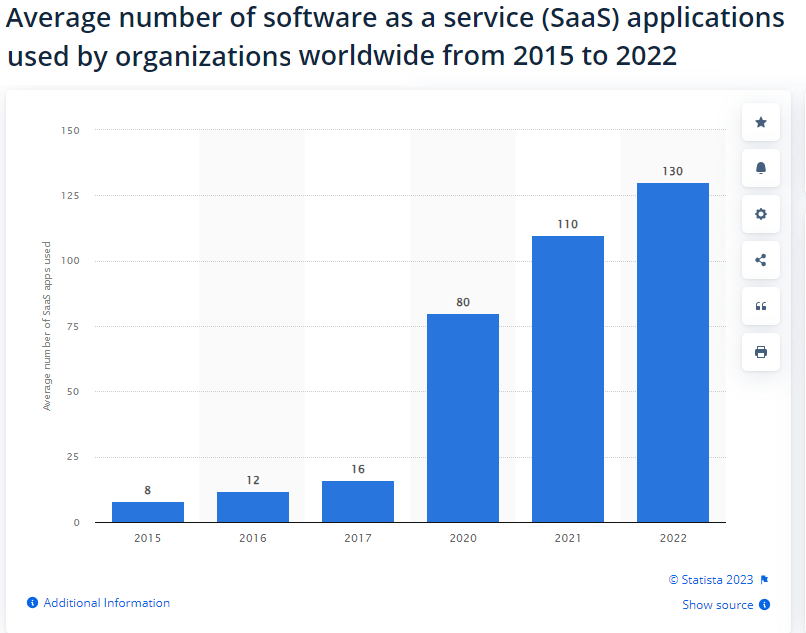
SaaS usage has skyrocketed in recent years (Image source Statista)
Consumer-focused Web giants like Google and Facebook faced scrutiny early on for their data collection and processing efforts. There was pushback when users of “free” services like Gmail and social media apps discovered that they were paying for the service with their data, i.e. that they were the product.
But business SaaS vendors largely stayed under the radar regarding collection and use of their customers’ data, says Shiva Nathan, the CEO and founder of Onymos, a provider of a privacy-enhanced Web application framework.
“SaaS was a great thing back in the early 2000s,” Nathan says. “When the pendulum swung from on-premise data centers to the cloud, people didn’t think two steps ahead to say that, oh along with the infrastructure, we also moved our data too.”
SaaS providers are sitting on a veritable goldmine of customer data, and they’re under pressure to monetize it, often using AI. SaaS providers will often state that they collect customer data for something generic, such as “to improve the service,” which sounds good, but they often will use it for analytics or to train an AI model that the customer isn’t directly benefiting from. That raises problematic questions.
“Enterprise always thought that I’m paying for this service, which means that my data is not going to be misused or used for some other purposes,” Nathan tells Datanami. “The customers are just now getting aware that their data is being used by someone that they did not think was going to use the data.”
Uncertain Terms
The big problem is that many SaaS providers don’t clearly state what they’re doing with the data, and use intentionally vague language in their customer agreements, Nathan says.
Zoom was caught red handed collecting audio, video, and transcripts of calls to build AI models without consent until it was called out on the practice. Even then, it took the company a couple tries before it spelled out its data collection instances in plain English.
Many other SaaS vendors have successfully avoided scrutiny regarding their data collection efforts up until this point, Nathan says. “People didn’t think that far ahead,” he says. “If you use Stripe, it gets all your financial data. If you use Octa, it gets all your authentication data.”

(D.Georgiev/Shutterstock)
SaaS vendors are intentionally vague in their terms of service, which gives them plausible deniability, Nathan says. “Their attorneys are smart enough to write the contract in such a broad language that they’re not breaking the terms,” he says.
When a SaaS vendor uses its customers’ data to train machine learning models, it’s impossible to back that data out. Just as a child can’t unsee an unsettling TV show, an ML model can’t be turned back in time to forget what it’s learned, Nathan says.
Using this data to train AI models is a clear violation of GDPR and other privacy laws, Nathan says, because no consent was given in the first place, and there’s no way to pull the private data back out of the model. Things are exacerbated when other customers’ data is inadvertently collected.
“The whole Titanic-heading-to-the-iceberg moment is going to happen where the service providers have to go back and look at their customers’ data usage and most of the time it’s not their customer, it’s their customers’ customer,” he says. “We will have lawsuits on this soon.”
It’s worth noting that this dynamic has impacted OpenAI, maker of GPT-4 and ChatGPT. OpenAI CEO Sam Altman has repeatedly said OpenAI does not use any data sent to the company’s AI models to train the models. But many companies clearly are suspicious of that claim, and in turn are seeking to build their own large language models, which they will control by running in house or in their own cloud account.
Privacy as Feature
As businesses become savvier to the way their data is being monetized by SaaS vendors, they will begin to demand more options to opt out of any data sharing, or to receive some benefit. Just as Apple has made privacy a core feature of its iOS ecosystem, vendors will also learn that privacy has value in the market for B2B services, which will help steer the market.

Shiva Nathan is the CEO and founder of Onymos
Nathan is betting that his business model with Onymos–which provides a privacy-protected framework for hosting Web, mobile, and IoT applications–will resonate in the broader B2B SaaS ecosystem. Smaller vendors that are scraping for market share will either not collect any customer data or ensure that any sensitive data is obfuscated and anonymized before it makes its way into the model.
By putting businesses back in charge of their own data, it will not only protect the privacy of businesses and their customers, but lower the surface area for data-hungry hackers to attack–all while enabling customers to use AI on their own data, Nathan says.
“The fundamental paradigm that we are studying is that there doesn’t need to even be a [single] honeypot,” he says. “Honey can be strewn all around the place, and the algorithms can be run on the honey. It’s a different paradigm that we’re trying to push to the market.”
Unfortunately, this new paradigm won’t likely change the practices of the monopolists, who will continue to extract as much data from customers as possible, Nathan says.
“The most monopolistic SaaS provider would say, if you want to use my service, I get your data. You don’t have any other recourse,” he says. “It will make the larger operations that are powerful become even more powerful.”
Related Items:
Anger Builds Over Big Tech’s Big Data Abuses
Crazy Idea No. 46: Making Big Data Beneficial for All
Big Data Backlash: A Rights Movement Gains Steam
Leading Solution Providers









Tabor Network
















