

February 28, 2023
Forrester Shares the 411 on Data Fabric 2.0

(CodexSerafinius/Shutterstock)
Since the data fabric concept debuted a few years ago, it has become a popular method for enterprises to integrate disparate data management tools. Fabrics are yielding dividends for users, but nothing stays still in big data for long, which is why Forrester is discussing what’s new in data fabric 2.0.
As data volumes expanded and the problems of disconnected data silos became more became acute, data fabrics emerged as the connective tissue to help enterprises cope. By linking together the various data management tools that enterprises use to ingest, cleanse, transform, secure, and govern the data at the metadata layer, data fabrics can alleviate big data management pain and help get on with their advanced analytics, data science, and AI projects.
Data fabric 2.0 is marked by several enhancements over first-generation fabrics, most notably with the expansion of data intelligence across the stack, says Forrester Vice President and Principal Analyst Noel Yuhanna, who co-authored a recent Forrester report titled “Data Fabric 2.0 for Connected Intelligence.”
“What we see in 2.0 is more intelligence coming into the platform itself,” Yuhanna says. “1.0 was just getting all the data management functions together, so we can accelerate those use cases…. And 2.0 takes it to the next level, which is more about the intelligence coming into the platform.”
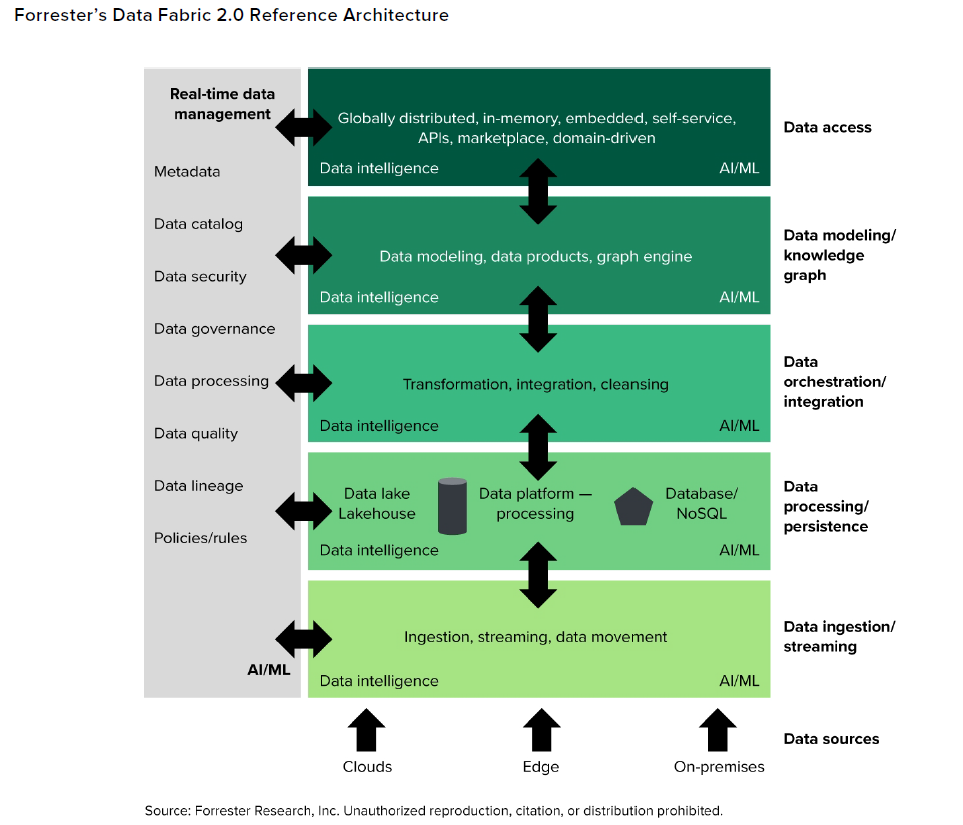
Image courtesy Forrester
With data fabric 2.0, the various products that make up the fabric will be capable of recognizing different types of data, Yuhanna says. For example, it will be able to identify credit card data coming into the fabric via one channel, he says, and know which other data is relevant.
“It probably knows that, hey, I need to connect this data which I loaded yesterday, with data which I loaded two weeks ago,” he says. “The intelligence is coming into play, which I think is very important. This is going to be a very important direction in the next five to 10 years for the journey of data fabric. The intelligence will be the most important element of data fabrics going forward.”
Much of the intelligence will be driven by having metadata shared across the various products that make up the fabric, Yuhanna says. Master data management (MDM) tools will also become more prominent in data fabrics, and will help ensure that enterprise are using the best data for a given task. In some cases, MDM projects will live next to data fabrics, while in others, the data fabric itself will function as the MDM, he says.
Graph engines will also become more common in data fabric deployments in the future. Graph databases, also known as knowledge graphs, will help to drive intelligence with data fabric 2.0, Yuhanna says.
“Graph engine is all about having graph capabilities to connect the dots together,” he says. “When you integrate two or four sources of data, it’s not a big deal. You can manually do some of this. Think about hundreds of sources of data coming in, or thousands of sources. It becomes humanly impossible to integrate them. That’s why you need an engine, like a graph engine, to really start to do the integration work.”
Not all data fabric vendors currently offer graph engines, but Yuhanna says that more vendors will be adding them to help connect the dots in the future. “I think this is going to be a huge requirement going forward for all of the vendors to increate graph engine,” he says. “As people mature their systems and platforms with data fabric, this becomes a critical requirement.”
Data fabric 2.0 is also marked by more real-time connectivity. Since the pandemic began, consumers have been putting pressure on companies to deliver better and faster service online. When those business requirements get translated to the IT departments, it means more adoption of streaming data systems, such as Apache Kafka and Amazon Kinesis.

Forrester analyst Noel Yuhanna has helped define the data fabric category
For large enterprises, just shipping data through faster pipes is one thing, but ensuring that the freshest data is available for the myriad of connected data services is something else. That’s where data fabric 2.0 comes in.
“The fact is, [data] pipelining is becoming more integrated,” Yuhanna says. “So it means you can get…these data sources coming in quickly to the fabric.”
One big retailer that has adopted streaming data in their data fabric is able to assemble all the information about customers within 10 seconds of that customer calling into the main hotline, Yuhanna says.
“By the time the custom gets connected, they already know exactly where this customer is calling in from, what are his likes and dislikes, and what are the potential opportunities for us,” he says. “This is happening real time in the fabric.”
Data fabric 2.0 will also make more room for data security and regulatory compliance concerns. Data security and data governance have always been first-class members of the data fabric, but emerging concerns amid tighter industry regulations around data storage and processing is pushing the concern higher up the stack.
Yuhanna recalls how one Forrester client found a novel use for a data fabric in this arena. The bank had thousands of users, and during an audit, it discovered that some former employees still retained their access to certain underlying systems. 
“They said, hey we can use a fabric that’s more centralized for security, authentication, authorization, and access control, as opposed to having it in the underlying systems,” the analyst says. “They implement that in four to six months and they got very good success. The auditors love that approach because it was more centralized. They knew exactly who was getting what access to data within the organization. And all the processes also have to connect through his fabric route. It become like LDAP, so to speak, for data access.”
Data fabric is about centralizing technologies and processes involved in the management of data. With data fabric 1.0, that mostly involved internal data, such as data from ERP and CRM systems. But it should come as no surprise that with data fabric 2.0, external data and data living on the edge will be brought more into the central data fold.
Forrester clients are looking to data fabrics to help integrate an array of external data, including social data, credit card data, government data, and data from open data initiatives, Yuhanna says.
“We’re starting to see the fabric expanding outside of the organization,” he says. “It’s become a more global trend. I think the global fabric play a big role because at the end of the day, you can connect multiple of these environments together, internally but also generally as well.”
The edge figures to play a central role in data fabric 2.0, too. While Yuhanna is tracking the emergence of cloud-based data fabric as a service (DFaaS) offerings that provide centralized access to data management for customers’ data living in a single cloud, there will also be a place for data fabrics that extend out beyond a single cloud.
“That’s why the fabric actually becomes a very strong value proposition, to connect the dots between the on-premise world, the cloud world, the multi-cloud world, and the edge,” Yuanna says
What’s more, data fabrics are also starting to cover smart devices and connected cars. “They also need consistent data, they need trusted data, they also need real time data for business,” Yuhanna says. “So we’re seeing that fabric is moving to the edge for those use cases, as well. But this is very early for the fabric in that lane.”
You can read Forrester’s new report “Data Fabric 2.0 For Connected Intelligence” at this link.
Related Items:
Data Mesh Vs. Data Fabric: Understanding the Differences
Data Fabric Brings Data Together for Timely Decisions
These 15 Data Fabrics Made the Cut in Forrester’s Wave
Applications:
Data Management
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Forrester
Leading Solution Providers









Tabor Network
















