

January 31, 2023
AWS Announces General Availability of OpenSearch Serverless

Amazon Web Services has announced the general availability of its Amazon OpenSearch Serverless service. Unveiled at the company’s recent re:Invent conference, this serverless option is meant to drive use cases like website search and real-time application monitoring where sudden spikes in usage can make capacity planning challenging for developers. AWS says OpenSearch Serverless automatically provisions, configures, and scales OpenSearch infrastructure to deliver fast data ingestion and millisecond query responses, even for unpredictable and intermittent workloads.
Data ingestion and search resources scale independently in OpenSearch Serverless, and it decouples storage and compute: “OpenSearch Serverless separates storage and compute components, and indexing and query compute, so they can be managed and scaled independently. OpenSearch Serverless uses Amazon S3 as the primary data storage for indexes, so you don’t need to worry about durability. We have decoupled your configuration choices from the proper provisioning of resources, so configuration mistakes won’t cause outages. OpenSearch Serverless will also apply security and software updates in the future with no disruption to your workloads,” wrote Pavani Baddepudi, a senior product manager working in search services at AWS, in an announcement.
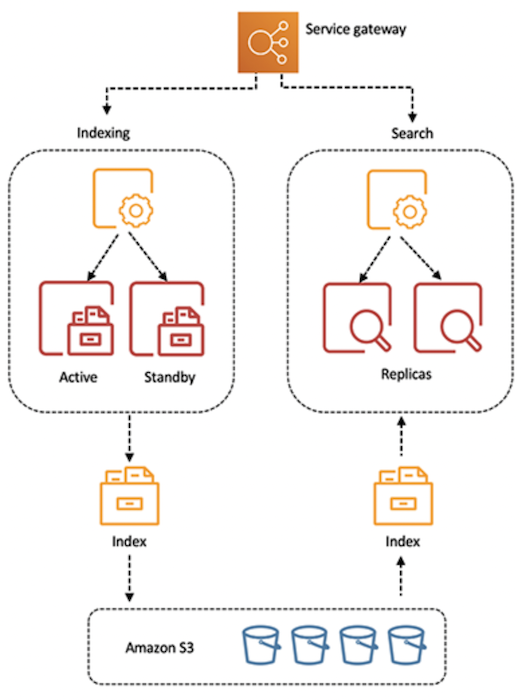
OpenSearch Serverless features an architecture where storage and compute resources are decoupled. (Source: AWS)
AWS asserts that there is no need for users to size or provision resources upfront or to overprovision for peak load in production environments. Therefore, users only pay for the compute and storage resources consumed. Users also have the ability to control retention and delete data using the APIs.
AWS highlights two target use cases for this service which are similar to OpenSearch. The first is time series analytics (also called log analytics) where the focus is on the analysis of large volumes of semi-structured metrics data in real-time for operational, security, and user behavior insights. The second use case is web search such as what is used for ecommerce website search and content search, as well as search-powered customer applications in internal networks such as application search, content management systems, and legal documents.
Beginning users of OpenSearch Serverless will create a collection, or a logical grouping of indexed data that works together to support a workload while physical resources are automatically managed in the backend: “You don’t have to declare how much compute or storage is needed or monitor the system to make sure it’s running well. To adeptly handle the two predominant workloads, OpenSearch Serverless applies different sharding and indexing strategies. Therefore, in the workflow to create a collection, you must define the collection type—time series or search. You don’t have to worry about re-indexing or rollover of indexes to support your growing data sizes, because it’s handled automatically by the system,” explained Baddepudi.
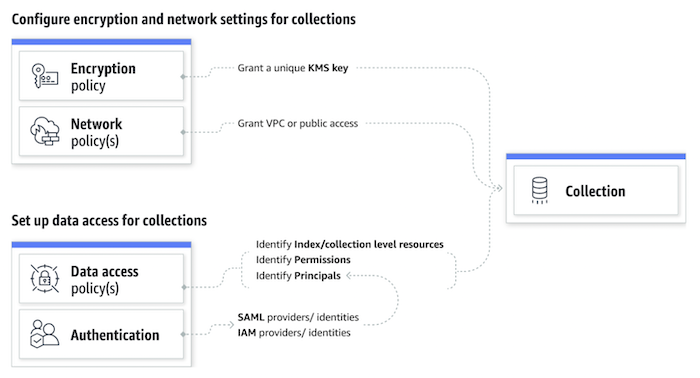
Data access and security configurations for OpenSearch Serverless. (Source: AWS)
Aside from the decoupled architecture, security was also a main consideration in the design of OpenSearch Serverless. After creating a new collection, users can make data access configuration choices regarding encryption keys, network access through a public endpoint or VPC, and who has permission to access the collection. There are granular collection-level and account-level configurations to create security policies for all collections and indexes. These network and data access policies can be updated at any time. Additionally, OpenSearch Dashboards can be accessed using SAML and AWS Identity and Access Management credentials, and all data is encrypted in transit and at rest by default.
OpenSearch Serverless builds on OpenSearch, which is a fork of another popular search engine, Elasticsearch. Amazon had previously introduced a managed Elasticsearch service, prompting a trademark dispute that led Elasticsearch to move its software away from open source into a less permissive license. AWS then launched OpenSearch as a fork and then settled the dispute, as it no longer associated the Elasticsearch brand with its own search product.
OpenSearch Serverless was previously available in preview, and its general availability also comes with enhancements, including scale-in support and availability in three new regions for a total of eight global AWS regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Ireland). More details can be found here or in a video from the product’s launch at AWS re:Invent.
Related Items:
AWS Moves Up the Application Stack
AWS Introduces Amazon Security Lake and AWS Clean Rooms
Most AWS Analytics Customers Will Go Serverless, VP Says
Vendors:
AWS
Leading Solution Providers

















