


May 24, 2022
The Rise and Fall of Data Governance (Again)

(alphaspirit.it/Shutterstock)
Data governance has had more than its fair share of spins through the hype cycle. It burst on the scene in the late 90s with metadata management as a seemingly silver bullet for making data actionable and trustworthy.
A decade and a half later, the industry was littered with failed, C-suite driven initiatives to try and manually catalog every data asset. So many data teams drowned it was unfathomable any would ever dare again set sail on such a hubristic odyssey.
And yet, many data teams are convinced that today the tides have turned!
Data governance remains vital, perhaps even more so as data volume levels rise and disruptive tidal waves of data regulation such as GDPR wash across the industry.
Driven by these outside forces, data teams have started to convince themselves that maybe, just maybe, machine learning automation can tame the storm and make cataloging data assets possible this time around.
Unfortunately, many of these new data governance initiatives are destined to sink by focusing on technology to the detriment of culture and process.
The reality is for teams to improve their data governance posture they need to not only have visibility into their data, but also treat it like a product, be domain-first, and establish data quality as a prerequisite.
Treat Data Governance Like a Product — Don’t Treat a Product Like its Data Governance
Data governance is a big challenge, and so it’s tempting to try and tackle it with a big solution.
Typically, data governance initiatives will start with a data leader decreeing the seemingly agreeable objective, “We will catalog all the things and assign owners for all of our data assets end-to-end so it is accessible, meaningful, compliant, and reliable.”
The first problem with this initiative is how it originated. Just as successful companies are customer focused, data teams must focus on their data consumers and internal customers, too.
I guarantee no one in the marketing department asked you for a data catalog. They asked for useful reports and more reliable dashboards.
No one in the compliance department asked for a data catalog either. They asked for visibility into the location of regulated and personally identifiable information and who has access.
But rather than setting course for these achievable destinations, some data teams are looking beyond the horizon without a business requirement in sight. There is no minimum viable product. There is no customer feedback and iteration. There are only big ideas and broken promises.
And don’t get me wrong: catalogs still have an important role to play. But even the best technologies are no substitute for good processes.
Too much emphasis is placed on the tactic (cataloging data assets) and not enough on the goals (accessible, meaningful, compliant, reliable data). It’s no wonder sails start to deflate once teams realize they need more specific coordinates.
Let’s revisit the earlier decree from leadership: “We will catalog all the things and assign owners for all of our data assets end-to-end so it is accessible, meaningful, compliant, and reliable.”
- What do we mean by “catalog?” How will the data be organized? Who will it be built for? What level of detail will it include? Will it have real-time lineage? At what level?
- What exactly are “all the things?” What is a “data asset?” Is it just tables or does it mean SQL queries and downstream reports, too?
- What do we mean by “owners?” Who owns the catalog? How will they be assigned, and what are they responsible for? Are we talking about the centralized data stewards of yore?
- What is “end-to-end?” What is the catalog’s scope? ” Does it include both structured and unstructured data? If so, how can unstructured data be cataloged before it is processed into a form that has intent, meaning, and purpose?
Cataloging data without having answers to these questions can be like cataloging water, its constantly moving and changing states, making it nearly impossible to document.
Be Domain-First
The reason these points are so hard to plot is because teams are navigating without a compass: the needs of the business. Specifically, the needs of the different business domains who will actually be using the data.
Without a business context, there isn’t a right answer let alone prioritization. Mitigating governance gaps is a monumental undertaking, and it’s impossible to prioritize these without a full understanding of which data assets are actually being accessed by your company and for what purpose.
Just as we’ve moved toward cloud-first and mobile-first approaches, data teams are beginning to adopt a domain-first approach, often referred to as the data mesh. This decentralized approach distributes data ownership to data teams within different departments that develop and maintain data products. And in the process, this puts data teams closer to the business.
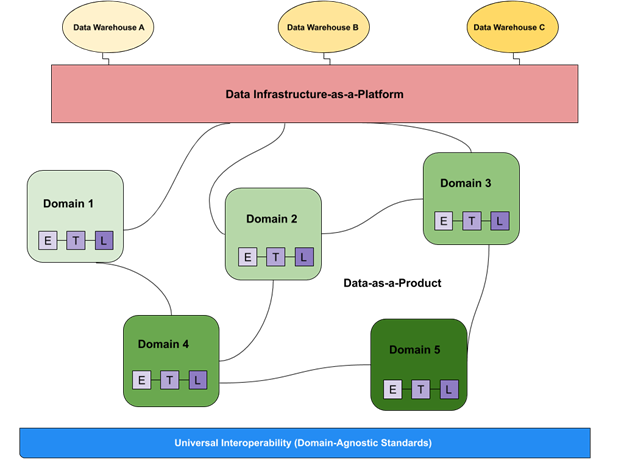
At a high level, a data mesh is composed of three separate components: data sources, data infrastructure, and domain-oriented data pipelines managed by functional owners. Underlying the data mesh architecture is a layer of universal interoperability, reflecting domain-agnostic standards, as well as observability and governance. (Image courtesy of Monte Carlo).
A modern data governance approach needs to federate the meaning of data across these domains. It’s important to understand how these data domains relate to each other and what aspects of the aggregate view are important.
This type of data discovery can provide a domain-specific, dynamic understanding of your data based on how it’s being ingested, stored, aggregated, and used by a set of specific consumers.
Data governance must also go beyond describing the data to understanding its purpose. How a producer of data might describe an asset would be very different from how a consumer of this data understands its function, and even between one consumer of data to another there might be a vast difference in terms of understanding the meaning ascribed to the data.
A domain-first approach can give shared meaning to and requirements for the data within the operational workflow of the business.
Data Quality is a Prerequisite to Data Governance
No technology can solve sloppy data processes or organizational culture. Even as more data assets are automatically documented and cataloged, more issues are generated beneath the surface. If you’re taking on more water than you’re bailing out, you sink.
Software engineering and the discipline of site reliability engineering have evolved to a 5 9s availability standard (as in 99.999%) for their SLAs. Unfortunately, most data teams do not have any internal SLAs detailing the expected performance of their data products and can struggle with setting and documenting data quality metrics such as data downtime.

(Basjan Bernard/Shutterstock)
It’s hard to blame data teams for having some sloppy habits when data has been too fast, the consequences of disorganized data too small, and data engineers too few. However, data reliability engineering must be prioritized for any data governance initiative to have a reasonable chance at success.
It also must be first for the governance initiative to be successful. To put it simply, if you catalog, document, and organize a broken system you are just going to have to do it again once it’s fixed.
Instilling good data quality practices can also give teams a headstart on achieving data governance goals by moving visibility from the ideal state to the current (real-time) state.
For example, without real-time lineage, it’s impossible to know how PII or other regulated data sprawls. Think about it for a second: even if you’re using the fanciest data catalog on the market, your governance is only as good as your knowledge about where that data goes. If your pipelines aren’t reliable, neither is your data catalog.
Data Governance With a Purpose
My recommendation to data teams is to flip the data governance mission statement around. Start multiple smaller initiatives each focused on one specific goal of making data more accessible, meaningful, compliant, or reliable.
Treat your data governance initiatives like a product and listen to your consumers to understand priorities, workflows, and goals. Ship and iterate.
Data governance has marooned many data teams, but by making business driven processes your north star you can find calm waters.
About the author: Barr Moses is the CEO and co-founder of Monte Carlo, the data reliability company, creator of the industry’s first end-to-end data observability platform.
Related Items:
Monte Carlo Hits the Circuit Breaker on Bad Data
Finding the Data Access Governance Sweet Spot
Security, Privacy, and Governance at the Data Crossroads in ‘22
Applications:
Enterprise Analytics
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Monte Carlo
Leading Solution Providers
















