

December 12, 2019
Data Pipelines of a Higher Order

(posteriori/Shutterstock)
Data pipelines are being constructed everywhere these days, moving huge swaths of data for a wide variety of operational and analytical needs. There’s no doubt that all these data pipelines are keeping data engineers busy and in high demand (and highly paid, to boot). But are these pipelines and engineers working at optimal efficiency? The folks at Ascend.io, which develops a data pipeline automation service based on Kubernetes and Apache Spark, have their doubts.
Data is the lifeblood of digital organizations, providing the critical pieces of information that are required to make business work. But data is useless if it’s not at the right place at the right time, which is why organizations of all stripes are frantically laying data pipelines across the public Internet and private networks with the goal of moving data from the point of origin to its destination, no matter of it’s a system of engagement, a data warehouses, a data lake, a warm data staging ground, or a cold data archive.
Data engineers are often called upon to construct these data pipelines, and they’re often put together in a manual fashion, using SQL, Spark, Python, and other technologies. Once they’re put into production, the engineer must orchestrate the movement of data through those pipes, often via ETL jobs. Maybe they’re using a tool like Airflow to manage those jobs, or maybe they’re not. And when the data coming out of the pipes develops an issue, the engineer typically fixes it by hand.
All of this hands-on, manual interaction with data pipelines is a concern to Sean Knapp, the CEO of Ascend.io. Knapp founded Ascend.io four years ago because he thought there was a better way to approach the data pipeline lifecycle.
“Every data business needs data pipelines to fulfill their data products,” Knapp says. “But the challenges in building data pipelines is it’s still very fundamentally difficult. Data engineers are spending the lion’s share of their time not even architecting and designing data pipelines, but frankly maintaining them.”
Ascend.io addresses that with a tool that automates much of this work. “Our belief is the notion of a pipeline itself should really be a dynamic construct,” Knapp says. “Pipelines should go up. They should go down. They should be responsive to the data. A pipeline should be dynamically constructed by an automated system.”
Declarative Pipelines
Knapp attacked the problem by envisioning what a higher order data pipeline would look like. Instead of requiring the engineer to get bogged down with the technical details of a data pipeline, he could describe what he wanted to happen at a higher level, in a blueprint, and then let an intelligent piece of software automatically build the production system.
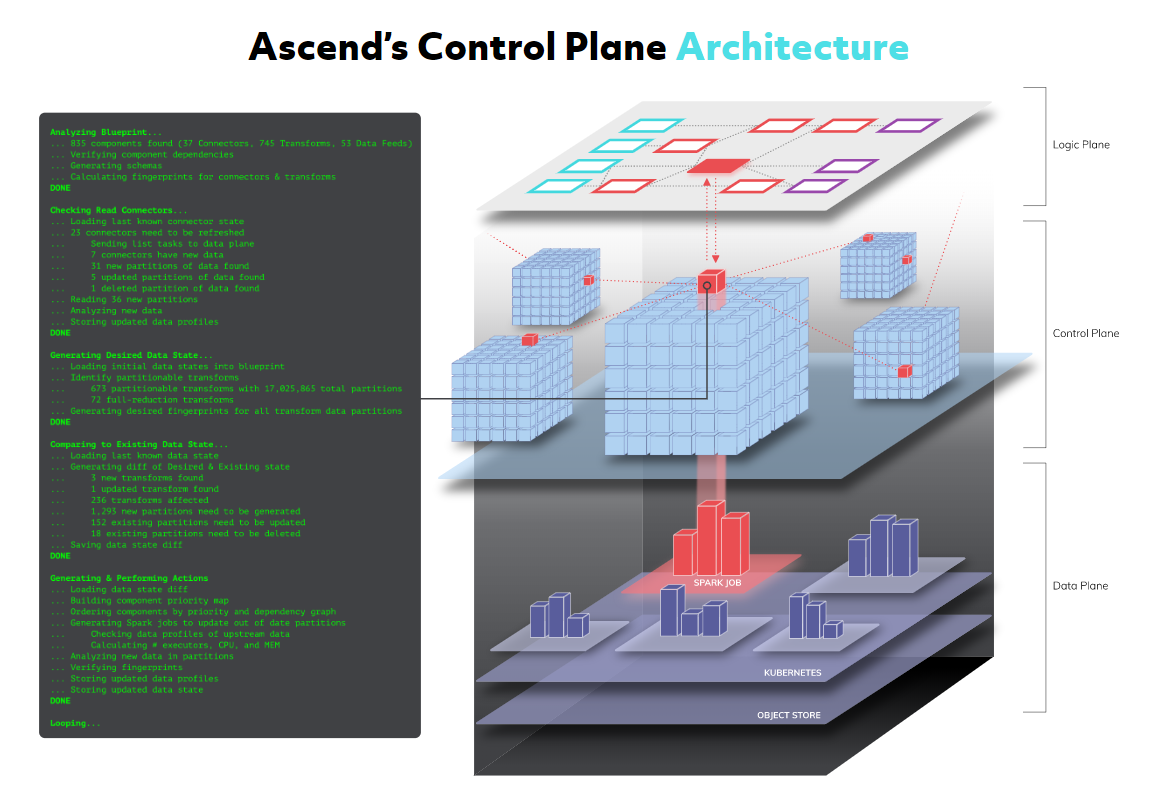
Ascend’s Control Plane architecture
“What we find with most engineering tools is you start with an imperative model,” Knapp tells Datanami. “So from a data pipeline perspective, they perform some set of tasks on some trigger, some cadence, or some interval. It always kind of starts there. Most technology domains trend towards higher degrees of optimizing, abstraction, which is usually borne and driven by a declarative model.”
At Ascend.io, Knapp and his team developed an automated pipeline builder that works in a declarative manner. The user defines what she wants the pipeline to do following a template, and the software takes care of the nitty-gritty details of building the pipeline, filling it with data, doing some transformation upon it, and then turning the pipeline off.
The most critical element for Ascend might be the control plane, which is the part that maintains an understanding of what’s happened in the data pipelines, and maintaining state for the entire data ecosystem, Knapp says.
“It knows what’s been calculated, why it’s been calculated, where it can move from, and can constantly be doing integrity checks around whether or not the data still matches the logic that the engineer describes,” he says. “Nobody has ever done that before.”
Data Validation
As a former data engineer, Knapp is aware that engineers spend a large portion of their time building tools that let them validate that the data is correct. “We’re implementing all these heuristics and safeguards in our data pipelines to essentially guarantee that the data we’re generating is what we intend it to be,” he says.
“There are things we’re always trying to protect against,” Knapp continues. “Things like late arriving data. I already did an ETL and analytics pipeline for yesterday’s store, but the data came in two days later. Do I update that or not? How long should I be looking across that window? Do I change state for that? Things like I changed the logic. Where did all this data go? Do I have to update the calculations based on those things? These are the kinds of patterns that we end up implementing in data pipelines. “

(posteriori/Shutterstock)
The Ascend.io software allows data engineers to function more like data architects, according to Knapp. The engineer can dictate where specific pieces of data will flow, what transformations will occur to it along the way, and then the Ascend software will actually execute it, including spinning up the necessary Kubernetes containers, instantiating the necessary Spark clusters, and processing the data according to the plan. That takes the data engineer off the hook for getting his hands dirty with the actual plumbing, and lets him concentrate on higher level problems.
The pipelines constructed by Ascend.io are responsive to changing data and changing conditions in data transformations defined by the engineer, Knapp says.
“We dynamically launch Spark clusters and Spark jobs that push data through,” he says. “If somebody changes the logic, we automatically know, oh my gosh, we just deployed some new changes, we need two years of data backflow. Let us dynamically scale this for you and construct a new pipeline for the backfill automatically.”
Common Interfaces
The Ascend.io software presents users with an array of interfaces, including a GUI, a software development kit, and APIs for SQL, Python, PySpark, and YAML. Engineers can work with pipelines in a data science notebook, like Juypter, and access Parquet files directly, if they want. Integration with CICD tools like as Git, Gitlabs, Github, Jenkins, and CircleCI ensure that pipeline deployments are well tracked.
Another neat trick is that Ascend.io exposes intermediate data sets to engineers, which allows them to build pipelines faster, and also build faster pipelines, Knapp says.
“If I’m doing an ETL pipeline, there are intermediate stages that I want to persist, so I don’t have to repeat a bunch of calculations,” he says. “This is something that ends up becoming really hard because you have to do things like lineage tracking to know when to invalidate those intermediate persisted data sets. And that’s one of the things that Ascend does automatically.”![]()
In addition to providing access to those intermediate data stages, Ascend also prevents duplication of effort and duplication of data. This is an important feature for organizations that are employing lots of engineers to build many data pipelines to keep application developers, BI analyst, and data scientists flush with good, clean data.
“We’re able to store all of this data fully de-duplicated in that BLOB store,” Knapp says. “We persist it here, but you may have copied your data pipelines and you have eight people running the same version of the pipeline. Our system knows it’s all the same operation happening in the pipeline, so our system automatically dedupes it…. We won’t even send job to Spark to rerun those data sets, because we know that somebody had already generated the data before.”
Hybridized Data Workflows
At the 30,000-foot level, there are two types of data processing jobs: batch and real time. In a similar vein, streaming data systems like Apache Kafka are typically good at pushing data out, while traditional databases handle queries, which are more like “pull” requests. But these differences aren’t important in the Ascend scheme of things, according to Knapp.
“Most developer over time want to hybridize this notion of batch and streaming, and push and pull,” he says. “These are artificial constructs that we have to worry about as engineers. But as the business leader, I know that I want to move my data from point A to point B with some transformation in roughly X amount of time. and I want to know also whether or not that calculations is still valid.”
The company competes with other ETL vendors, such as Talend and Informatica. It also competes to some extent what Confluent is doing with its hosted Kafka options, as well as the open source Airflow and Kubeflow data orchestration tools. On the cloud, Amazon Web Services‘ Glue, Google Cloud’s Data Fusion, and Microsoft Azure’s Data Factory are the closest competitors, Knapp says.
Ascend.io is available on AWS, Google Cloud, and Microsoft Azure. Pricing starts at $1,000 per month with Ascend Standard, plus fees for using storage. For more information, check out its website at www.ascend.io.
Related Items:
Kubeflow Emerges for ML Workflow Automation
Merging Batch and Stream Processing in a Post Lambda World
Applications:
Complex Event Processing
Technologies:
Frameworks
Leading Solution Providers

















