


March 6, 2017
What’s In the Pipeline for Apache Spark?

According to Apache Spark creator Matei Zaharia, Spark will see a number of new features and enhancements to existing features in 2017, including the introduction of a standard binary data format, better integration with Kafka, and even the capability to run Spark on a laptop. But the big prize—automated creation of continuous applications in Spark—remains a long-term goal.
2016 was a huge year for the Apache Spark project, particularly with the launch of the new Structured Streaming API and ongoing work in Project Tungsten, which started in 2015 to improve performance by escaping the bounds of the JVM. But the user community around Spark is also exploding, with 300,000 people attending Spark meetups globally, a 3.6x increase, Zaharia said at last months’ Spark Summit East held in Boston, Massachusetts.
As the visionary behind Spark, Zaharia provided Spark Summit attendees with the lowdown on where Spark is going in the short and medium-term, including what’s coming with Spark version 2.2, which should be out soon, as well as subsequent releases.

Databricks wants to speed up emerging Spark workloads like deep learning using GPUs and FPGAs
Now that Spark has the core underlying engine that it wants in place in Structured Streaming–which is built on Spark SQL and Spark Streaming APIs–the Spark community is working to fill in some of the gaps around Structured Streaming to make it easier to develop applications and keep it up-to-date with evolving hardware and software requirements.
Zaharia, who is a co-founder and chief technologist of Databricks and an assistant professor of computer science at Stanford University, says that means working to make Spark work better with emerging hardware, including GPUs, FPGAs, and multi-core processors, and deep learning frameworks, like Google‘s TensorFlow and Intel‘s BigDL. Standardizing Spark’s I/O from a data standpoint is critical to enabling Spark to work better with these emerging processor architectures and deep learning frameworks, Zaharia says.
“Some of the stuff we’re working on now, first and foremost, is solidifying the interface between Spark and native code or external sets to allow them to pass data in an efficient way,” Zaharia says. “So we want to have a standard binary format to pass data in and out of Spark. We could use existing Tungsten format. Or maybe use something like Apache Arrow. This is still kind of being figured out.”
Also on the developer docket is enabling hardware GPU and FPGA accelerators to talk with the Spark scheduler. “This remains to be designed, but this will be another thing that makes this type of work easier,” Zaharia says.
The Spark community is also working to boost the performance of applications running under the SQL and Dataframe APIs, which have been stabilized. “We have a cost-based optimization coming likely in 2.2 or maybe 2.3,” Zaharia says. “This is work started at Huawei, and quite a few other companies have contributed.”

Python and R use have proliferated on Spark
When Spark first burst onto the big data scene in 2013, most Spark apps were being written in Java and Scala. But in 2016, the percentage of developers using Python and R with Spark rose dramatically, according to Databricks’ annual Spark survey. Zaharia and others at Databricks have taken notice. “In terms of Python and R, that’s something we’re doubling down on to improve both performance and usability,” he says.
Getting data into and out of Spark remains high on the priority list, and that will translate into better integration with JDBC, JSON, CSV, and Apache Kafka with upcoming releases, Zaharia says.
“A crazy but useful idea,” Zaharia says, “is to make Spark easy to run on single node. We see a lot of people develop stuff on laptops. Maybe they want to connect it to a cluster, or maybe they just want to process data locally. That’s actually kind of hard to do with Spark today… It’s kind of annoying.”
The Spark community is working to publish a single-node version of Spark for Python to PyPi, the Python Package Index, and is working on a similar packaging for the language R, he says.

Zaharia speaking at Spark Summit East in February
In terms of new operators, the next release of Spark will give users a new “Map with State” function, which Zaharia says has been highly requested, and a new session-based windowing function.
“We also have a lot of work planned on performance and latency,” Zaharia says. “Now that the basic engine is in, there’s a lot we can do to improve it, so expect to see some exiting work in these areas.”
In the long term, Databricks plans to continue the work of simplifying how developers build batch, interactive, and streaming applications using the Structured Streaming API and Project Tungsten. This falls under the rubric of “continuous applications” that Databricks started talking about last year when it originally launched the Structured Streaming API.
“Currently it’s really hard to build these because you have different systems for streaming, [interactive] serving, and batch,” Zaharia says. “You have to hook together these distributed systems, maybe Spark and HDFS or Redis or MySQL.”
This cross-platform integration was the bugaboo of enterprise application integration 20 years ago. And while the underlying systems and data types have changed, integration remains a hairy, mostly unsolved challenge today.
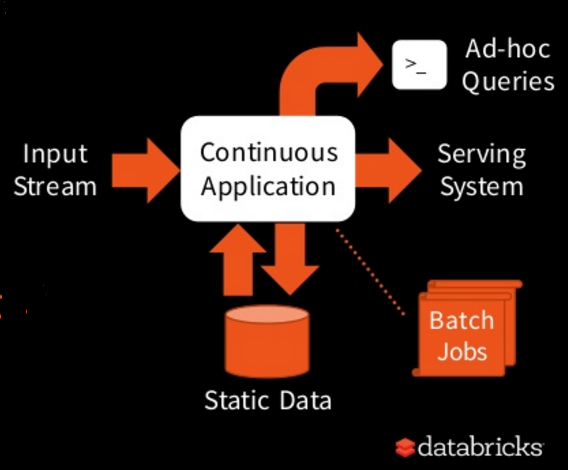
Databricks’ idea of continuous applications combines elements of batch, interactive, and real-time streaming
“When we talk with users, they say most of the work they spend is actually in hooking them up and making sure that when you read stuff, you only read it once, and you don’t forget where you were when there are crashes,” Zaharia says. “So what we’d like to get to is instead of you hooking them up by hand, you have a single high-level API that lets you build these so-called continuous applications that can not only compute on data inside Spark but also update and interact with external systems in a consistent way. This would save a ton of people a lot of time in building these applications.”
Combined with the auto-code generation capability that the Spark community is building— where “you just tell it what you want to compete and it will actually do this stuff,” as Zaharia says–this sounds like just what the big data community needs.
Related Items:
Spark Streaming: What Is It and Who’s Using It?
Databricks CEO on Streaming Analytics, Deep Learning, and SQL
Spark 2.0 to Introduce New ‘Structured Streaming’ Engine
Applications:
Artificial Intelligence
Leading Solution Providers
















