

November 11, 2015
AMPLab Releases Succinct, A New Way to Query Data in Spark
The folks at UC Berkeley’s’ AMPLab are starting to talk publicly about Succinct, a fast new in-memory data store aimed at enabling users to query large amounts of compressed data, in a fast and direct fashion. Early tests show Succinct can perform the same types of big data queries that popular NoSQL databases can do, but on systems one-tenth the size.
Succinct is an in-memory data store that enables the execution of complex queries directly on compressed data. It does this through a novel compression mechanism that embeds all of the information within the compressed representation of the data. In this manner, it can enable interactive queries of multiple gigabytes worth of database values on a system with relatively modest memory.
The problem of how best to store secondary attributes is one that has challenged database developers. Two basic approaches have been taken, AMPLab researchers Rachit Agarwal, Anurag Kahndelwal, and Ion Stoica, write in the October 2015 paper “Succinct: Enabling Queries on Compressed Data,” which can be download here.
“At one extreme, systems such as column oriented stores simply scan the data,” they write. “However, data scans incur high latency for large data sizes, and have limited throughput since queries typically touch all machines.”
At the other extreme are secondary indexes. “When stored in-memory, these indexes are not only fast, but can achieve high throughput since it is possible to execute each query on a single machine,” the AMPLab directors write. The main disadvantage of indexing? A high memory footprint, since the secondary indexes can be up to eight times (8x) bigger than the source data itself.
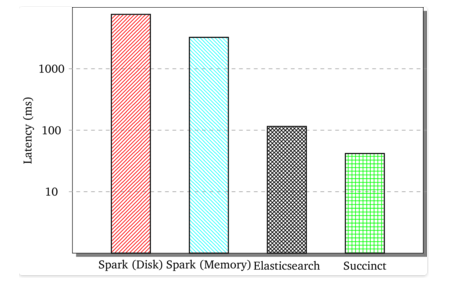
Succinct delivers queries faster than native Spark and ElasticSearch
Succinct delivers the same level of query throughput achieved through indexing but without the high memory footprint of secondary indexes. It achieves this by storing an “entropy-compressed representation of the input data that allows random access, enabling efficient storage and retrieval of data,” the researchers write. “Succinct’s data representation natively supports count, search, range and wildcard queries without storing indexes–all the required information is embedded within this compressed representation.”
Secondly, Succinct executes queries directly on the compressed representation, avoiding the need for data scans and decompression. “What makes Succinct a unique system,” the AMPLab researchers write, “is that it not only stores a compressed representation of the input data, but also provides functionality similar to systems that use indexes along with input data.”
AMPLab, which gave the world the Apache Spark framework, the Tachyon distributed file system, and the Mesos resource manager (as well as a dozen or so less-visible projects, like KeystoneML, the Akaros OS, CrowdDB, and more) has been working on Succinct for some time, but only recently ported it into Spark and supported Spark’s resilient distributed datasets (RDDs).
“We are very excited to announce the release of Succinct Spark, as a Spark package, that achieves a unique tradeoff–storage overhead no worse (and often lower) than data-scan based techniques and query latency comparable to index-based techniques,” Agarwal wrote last week on the AMPLab blog.
“Succinct Spark enables search (and a wide range of other queries) directly on compressed representation of the RDDs,” he continues. “What differentiates Succinct Spark is that queries are supported without storing any secondary indexes, without data scans and without data decompression–all the required information is embedded within the compressed RDD and queries are executed directly on the compressed RDD.”
According to Agarwal, Succinct allows users to use Spark as a document store similar to ElasticSearch. When used as a document store, Succinct Spark is 2.75x faster than ElasticSearch for search queries while requiring 2.5x lower storage, he says. Compared to native Spark writing to disk, it’s 75x faster.

The Berkeley Data Analytics Stack is BDAS.
The AMPLab has also tested Succinct against MongoDB and Cassandra, which support more complex data types than ElasticSearch’s key-value store. According to a 2014 Gigaom article, the researchers demonstrated how Succinct was able to store a 123GB dataset on a single machine with 64 GB of memory, whereas the NoSQL data stores required secondary indexes, which were spread across 16 servers, each with 64GB of memory.
Succinct isn’t ready to supplant those popular databases just yet, but it could provide the technical underpinning for radical new approaches to storing and accessing large amounts of data in the future.
“There are a large number of interesting follow up projects in AMPLab on Succinct exploring the fundamental limits to querying on compressed data, adding new applications on top of Succinct, and improving the performance for existing applications,” Agarwal writes. “We will write a lot more about these very exciting projects on Succinct webpage.”
The group has released open source code for Succinct, specifically for compressing RDDs in Spark and exposing DataFrames for Spark SQL. You can find downloads at http://succinct.cs.berkeley.edu.
Related Items:
Spark Gets New Machine Learning Framework: KeystoneML
Tachyon Nexus Gets $7.5M to Productize Big Data File System
Apache Spark Ecosystem Continues To Build
Applications:
Enterprise Analytics
Vendors:
AMPLab
Leading Solution Providers

















