

July 17, 2025
TigerData Unveils Tiger Lake to Bridge the Gap Between Postgres and Lakehouse
(Credits: TigerData.com)
TigerData today introduced Tiger Lake, an architecture it calls “the missing layer between Postgres and the lakehouse for the age of agents.” The release is part of the company’s effort to make it easier for developers to work with both real-time and historical data without relying on fragile pipelines or delayed batch syncing.
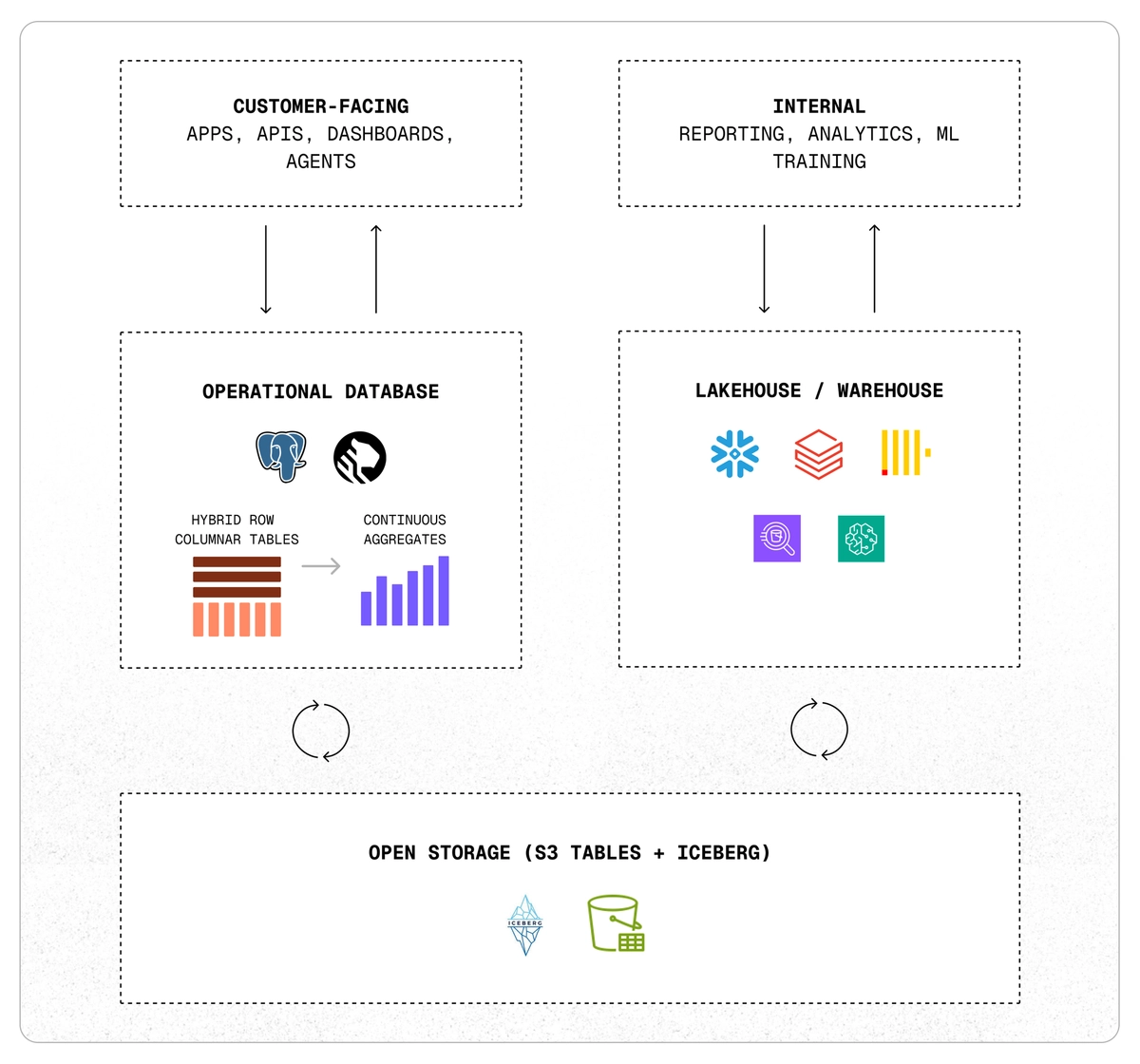
Tiger Lake is built directly into Tiger Postgres, the company’s customized version of PostgreSQL designed for real-time and analytical workloads. According to TigerData, the new architecture enables Postgres to sync with Iceberg-backed lakehouses like AWS S3 in both directions. The architecture currently offers native support for AWS S3 Tables, with integration for other lakehouse formats expected in future updates.
The goal with Tiger Lake is to give developers a simpler way to build applications, dashboards, and AI agents that depend on both fresh operational data and long-term analytical insights. TigerData says the architecture is meant to reduce complexity while keeping data systems flexible and open.
As co-founder and CTO Mike Freedman explains, Postgres has become the operational heart of many modern applications, but it has remained isolated from the lakehouse layer. “With Tiger Lake, we’ve built a native, bidirectional bridge between Postgres and the lakehouse,” he said. “It’s the architecture we believe the industry has been waiting for.”
Many teams currently rely on a patchwork of tools to move data between systems, often using Kafka, Flink, or custom scripts. That kind of setup can be fragile and expensive to maintain. TigerData says Tiger Lake replaces that complexity with built-in, real-time sync across Postgres and Iceberg.
(Credits:TigerData.com)
That was a key motivator for Speedcast. “We stitched together Kafka, Flink, and custom code to stream data from Postgres to Iceberg—it worked, but it was fragile and high-maintenance,” said Kevin Otten, Director of Technical Architecture at Speedcast. “Tiger Lake replaces all of that with native infrastructure. It’s not just simpler—it’s the architecture we wish we had from day one.”
Beyond syncing tables, a key feature of Tiger Lake is its ability to support a two-way flow of information. Operational data moves into the lakehouse for long-term storage or analysis, while results, like aggregates, ML features, or historical summaries, can be pushed back into Postgres for use in live applications.
TigerData emphasizes that one of the primary advantages of using Tiger Lake is that it allows users to avoid vendor lock-in. It uses open formats like Iceberg, runs on AWS S3, and connects with existing ecosystems for machine learning, monitoring, and analytics. Developers don’t need to rebuild their stack or switch platforms to use it.
This launch also reflects broader shifts in the data world. Postgres continues to rise in popularity for operational workloads, while Iceberg is gaining ground as the standard for open lakehouses. With more AI-driven apps needing access to both recent context and deep historical insight, Tiger Lake positions itself as the connective tissue between those layers.
For ML teams that need fresh features, analytics groups working with long-range trends, or developers building AI agents and dashboards, Tiger Lake could make it easier to connect different data systems without having to manage complex integrations.
If we zoom out a bit, the introduction of Tiger Lake aligns with TigerData’s broader focus. The company originally launched as Timescale in 2017, gaining recognition for its time-series extensions to PostgreSQL. But as it expanded into vector search, real-time analytics, and AI-native workloads, the team rebranded to TigerData earlier this year to better reflect its wider ambitions.

(Shutterstock AI Image)
“Modern applications don’t fit neatly into traditional database categories. They capture vast streams of data, power real-time analytics, and increasingly rely on intelligent agents that reason and act. These workloads—transactional, analytic, and agentic—require a new kind of operational database,” said Ajay Kulkarni, Co-founder and CEO. “That’s exactly what we’ve built at TigerData: a system that delivers speed without sacrifice.”
TigerData has grown to now serve more than 2,000 organizations, including Mistral, HuggingFace, Nvidia, Toyota, Tesla, NASA, JP Morgan Chase, Schneider Electric, Palo Alto Networks, and Caterpillar. It is also an AWS Partner with solutions available on AWS Marketplace. The company has raised over $180 million from backers like Benchmark, NEA, Redpoint, and Tiger Global.
The company says Tiger Lake is just the beginning. Future updates will include the ability to query Iceberg catalogs directly, send analytical results back into Postgres, and expand support for Iceberg-based workflows. TigerData is also working on performance upgrades, including faster large-scale inserts and a new storage architecture designed to make forks and replicas more efficient.
Related Items
AI One Emerges from Stealth to “End the Data Lake Era”
Rethinking Risk: The Role of Selective Retrieval in Data Lake Strategies
ETL vs ELT for Telemetry Data: Technical Approaches and Practical Tradeoffs
Vendors:
Tigerdata
Leading Solution Providers









Tabor Network
















