

July 1, 2025
Cloudflare Now Blocks Data Scrapers by Default

(solar22/Shutterstock)
Organizations that are concerned about big AI companies scraping their websites for training data may be interested to learn that Cloudflare, which handles 20% of Internet traffic, now blocks all data scraping by default.
“Starting today, website owners can choose if they want AI crawlers to access their content, and decide how AI companies can use it,” Cloudflare says in its July 1 announcement. “AI companies can also now clearly state their purpose–if their crawlers are used for training, inference, or search–to help website owners decide which crawlers to allow.”
The move, Cloudflare added, “is the first step toward a more sustainable future for both content creators and AI innovators.”
The practice of scraping public websites for data has come under fire in recent years as AI companies seek data to train their massive AI models. As large language models (LLMs) get bigger, they need more data to train on.
For example, when OpenAI launched GPT-2 back in 2019, the company trained the 1.5-billion parameter model on WebText, a 600-billion word novel training set that it created based on scraped links from Reddit users that was about 40GB.
When OpenAI launched GPT-3 in 2020, the 175-billion parameter LLM was trained on various open sources of data, including BookCorpus (Book1 and Book2), Common Crawl, Wikipedia, and WebText2. The training data amounted to about 499 billion tokens and 570 GB.
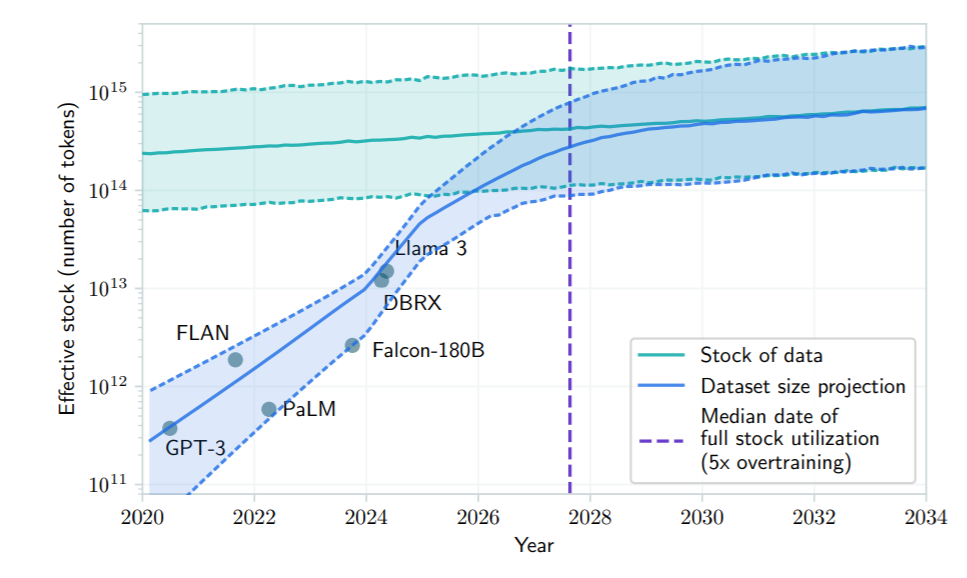
We will soon use up all novel human text data for LLM training, researchers say (Source: “Will we run out of data? Limits of LLM scaling based on human-generated data”)
OpenAI hasn’t publicly shared the size of GPT-4, which it launched in October 2023. But it’s estimated to be about 10x the size of GPT-3. The training set for GPT-4 has been reported to be about 13 trillion tokens, or about 10 trillion words.
As the size of the models gets bigger, training data gets harder to come by. “…[W]e could run out of data,” Dario Amodei, the CEO of Anthropic, told Dwarkesh Patel in a 2024 interview. “For various reasons, I think that’s not going to happen but if you look at it very naively we’re not that far from running out of data.”
So where do AI companies go to get training data? As most of the public Internet has already been scraped, AI companies increasingly are turning to private repositories of content hosted on the Web. Sometimes they ask for permission and pay for the data, and sometimes they do not.
For example, Reddit, the most popular news aggregation and social media websites in the world with 102 million daily active users, inked a deal with OpenAI in 2024 that gives the AI company access to data. Last month, Reddit sued Anthropic, claiming it accessed its website for training data without permission.
Cloudflare had already taken steps to help control data scraping. Stack Overflow, an online community of developers with 100 million monthly users, uses Cloudflare to authenticate users and block data scrapers, Prashanth Chandrasekar, Stack Overflow’s CEO, told BigDATAwire last month. Stack Overflow now offers its data to companies for AI training and other purposes via the Snowflake Marketplace.
“You’re getting immediate access to all the data,” Chandrasekar said. “It’s pre-indexed and the latency of that is super low. And most important, it’s licensed.”![]()
If the Internet is going to survive the age of AI, then creators of original content need to regain control over their data, Matthew Prince, co-founder and CEO of Cloudflare.
“Original content is what makes the Internet one of the greatest inventions in the last century, and it’s essential that creators continue making it. AI crawlers have been scraping content without limits,” Prince stated. “Our goal is to put the power back in the hands of creators, while still helping AI companies innovate. This is about safeguarding the future of a free and vibrant Internet with a new model that works for everyone.”
The move has the support of Roger Lynch, the CEO of Condé Nast, which owns and publishes a range of magazines and websites, including Vogue, The New Yorker, Vanity Fair, Wired, and Ars Technica, among many others.
“When AI companies can no longer take anything they want for free, it opens the door to sustainable innovation built on permission and partnership,” Lynch stated. “This is a critical step toward creating a fair value exchange on the Internet that protects creators, supports quality journalism and holds AI companies accountable.”
Steve Huffman, the co-founder and CEO of Reddit, also applauded the move. “AI companies, search engines, researchers, and anyone else crawling sites have to be who they say they are,” he said. “The whole ecosystem of creators, platforms, web users and crawlers will be better when crawling is more transparent and controlled, and Cloudflare’s efforts are a step in the right direction for everyone.”
Related Items:
Bad Vibes: Access to AI Training Data Sparks Legal Questions
Are We Running Out of Training Data for GenAI?
Leading Solution Providers

















