

June 25, 2025
LinkedIn Introduces Northguard, Its Replacement for Kafka
Facing scalability limitations with Apache Kafka for log file management, LinkedIn developed a new publish-and-subscribe (pub/sub) system that didn’t face the same limitations. The replacement pub/sub system that LinkedIn developed is called Northguard, and it’s now actively migrating its Kafka-based data to Northguard through a virtualized pub/sub layer dubbed Xinfra, the company announced today.
When Jay Kreps and his LinkedIn engineer colleagues Jun Rao and Neha Narkhede created Apache Kafka back in 2010, the social media site had 90 million members. At that time, the company struggled with major latency issues as it tried to load about 1 billion files per day into its Hadoop-based data infrastructure. To address this challenge, Kreps and company developed Kafka as a distributed, fault-tolerant, high-throughput, and scalable platform for building real-time data pipelines.
Kafka was a big hit internally at LinkedIn, as it provided a virtualization layer between the creation (or publishers) of data and the consumers (or subscribers) of data. It was used extensively internally, and was donated to the Apache Software Foundation the following year. Kreps, Rao, and Narkhede left LinkedIn and in 2014 co-founded Confluent, which last year generated nearly $1 billion in revenue.
Over the years, LinkedIn’s business expanded, and Kafka remained a central component of its internal and user-facing systems and applications. However, at some point, the volume of data being generated within LinkedIn surpassed Kafka’s capabilities. Today, with 1.2 billion users, its pub/sub systems are asked to ingest more than 32 trillion records per day, accounting for 17 PB across 400,000 topics, which run on more than 150 clusters accounting for more than 10,000 individual nodes.
This scale of data has surpassed Kafka’s capabilities, according to LinkedIn engineers Onur Karaman and Xiongqi Wu. “….[A]s LinkedIn grew and our use cases became more demanding, it became increasingly difficult to scale and operate Kafka,” the engineers wrote in a post on the LinkedIn Engineering Blog today. “That’s why we’re moving to the next step on our journey with Northguard, a log storage system with improved scalability and operability.
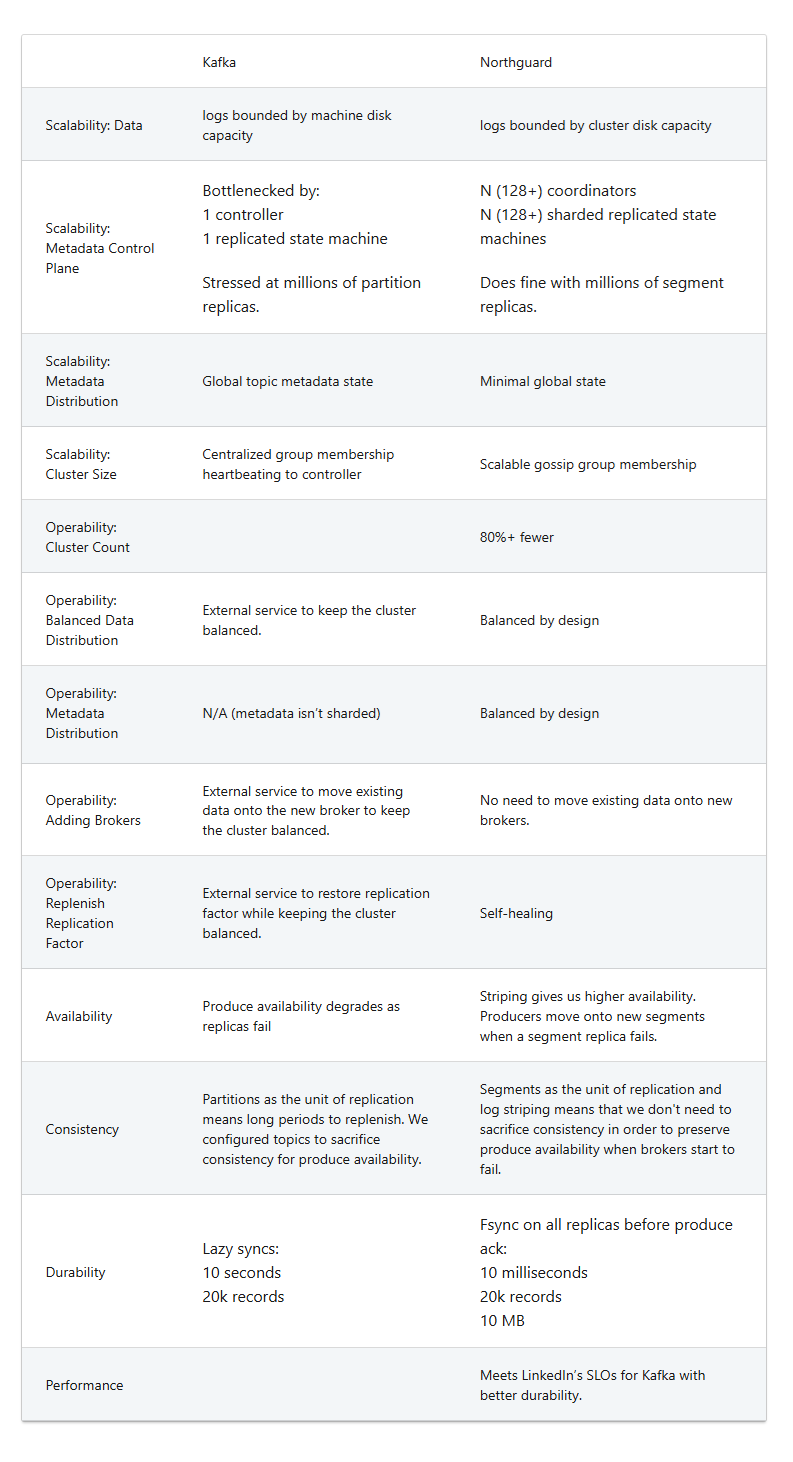
The Kafka challenges centered on five main areas, according to Karaman and Wu. Scaling the Kafka clusters became increasingly difficult as LinkedIn added more use cases, which resulted in more data and more metadata. With 150 Kafka clusters to manage, load balancing was also an issue.
The availability of data was also challenge, particularly since data replication was handled at the individual partition level. Consistency also became a problem, particularly when LinkedIn traded off consistency in favor of availability (due to the aforementioned partition replication issue). Lastly, durability of data suffered from weak guarantees.
“We needed a system that scales well not just in terms of data, but also in terms of its metadata and cluster size, all while supporting lights-out operations with even load distribution by design and fast cluster deployments, regardless of scale,” Karaman and Wu wrote. “Additionally, we required strong consistency in both our data and metadata, along with high throughput, low latency, highly available, high durability, low cost, compatibility with various types of hardware, pluggability, and testability.”
Northguard is a new pub/sub system that will replace Kafka at LinkedIn (Image courtesy LInkedIn)
The solution that Karaman and Wu came up with is a log storage system called Northguard. The engineer describe the core characteristics of the new system:
“To achieve high scalability, Northguard shards its data and metadata, maintains minimal global state, and uses a decentralized group membership protocol,” they write. “Its operability leans on log striping to distribute load across the cluster evenly by design. Northguard is run as a cluster of brokers which only interact with clients that connect to them and other brokers within the cluster.”
The Northguard data model is based on the concept of a record, which is composed of a key, a value, and user-defined header. A sequence of records in Northguard is called a segment, which is the minimal unit of replication in the system. Segments can be active, in which case they can be appended to, or they can be sealed, due to replica failure, reaching a maximum size limit of 1GB, or from the segment being active for more than one hour.
Similarly, a range is a sequence of segments in Northguard that’s bounded by a keyspace. These segments can be either active or sealed, the engineers write. A topic is a named collection of ranges that covers the full keyspace when combined. A topic’s range can be split into two ranges, or merged to create a new child range (but only if it falls within a unique “buddy range”). Topics can be sealed or deleted.

Onur Karaman (left) and Xiongqu Wu, the creators of Northguard at LinkedIn
Northguard is unary, the engineers write, which means that one request results in one response. The system stores data in the “fps store,” use a write-ahead log (WAL), and also maintains a “sparse index” in RocksDB.
“Appends are accumulated in a batch until sufficient time has passed (ex: 10 ms), the batch exceeds a configurable size, or the batch exceeds a configurable number of appends,” the engineers write. “Once ready to flush the batch, the store synchronously writes to the WAL, appends records to one or more segment files, fsyncs these files, and updates the index.”
Administrators work with topics by assigning them storage policies, which involves giving them names, retention periods that defines when the segments should be deleted, and a set of constraints. The constraints are defined by expressions and a set of keys and values that are bound to brokers, which are called attributes, the engineers write.
“Policies and attributes are a powerful abstraction,” Karaman and Wu write. “For example, Northguard itself has no native understanding of racks, datacenters, etc. Administrators at LinkedIn just encode this state in the policies and attributes on the brokers we deploy, making policies and attributes a generalized solution to rack-aware replica assignment. We even use policies and attributes to distribute replicas in a way that allows us to safely deploy builds and configs to clusters in constant time regardless of cluster size.”
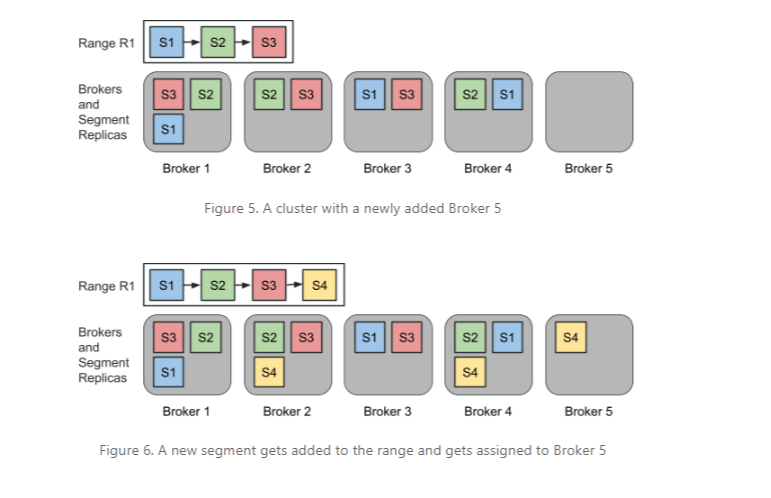
Northguard also implement the concept of log striping, which it uses to avoid instances of “resource skew” in clusters. Since Northguard has such a low-level unit of replication–the individual log, as opposed to a partition in Kafka, which caused its own set of problems–it would be prone to resource skew, which can be hard to deal with.
Differences between Kafka and Northguard (Image courtesy LinkedIn)
“Northguard ranges avoid these issues by implementing log striping, meaning that it breaks a log into smaller chunks for balancing IO load,” the engineers write. “These chunks have their own replica sets as opposed to the log. Ranges and segments are the Northguard analog of logs and chunks. Since segments are created relatively often, we don’t need to move existing segments onto new brokers. New brokers just organically start becoming segment replicas of new segments. This also means that unlucky combinations of segments landing on a broker aren’t an issue, as it will sort itself out when new segments are created and assigned to other brokers. The cluster balances on its own.”
The engineers also discuss Northguard’s metadata model, which is used for managing topics, ranges, and segments. The pub/sub system uses the concept of a “vnode” to store a shard of the cluster’s metadata. “A vnode is a fault-tolerant replicated state machine backed by Raft and acts as the core building block behind Northguard’s distributed metadata storage and metadata management,” Karaman and Wu write.
The business logic of the metadata lives inside a coordinator, which is the leader of a given vnode and where state is persisted. The coordinator tracks changes for topics owned by the vnode, such as sealing or deleting the topic and splitting or merging ranges from that topic, the engineers write. The way it manages metadata makes Northguard self-healing, they write.
A collection of vnodes assembled into a hash ring is called a Dynamically-Sharded Replicated State Machine (DS-RSM). By sharding metadata across vnodes using hashing, it can avoid metadata hotspots, the engineers write. Northguard uses a distributed system protocol called SWIM, which “employs random probing for failure detection but infection-style dissemination for membership changes and broadcasts,” the engineers write.
LinkedIn has begun implementing Northguard and replacing Kafka as the pub/sub system for certain applications. Since Northguard is written in C++ and Kafka was written in Java, there are compatibility issues. Another factor is the business critical nature of the applications and the inability to accept downtime.
To address these issues, LinkedIn developed a virtualized pub/sub layer called Xinfra (pronounced ZIN-frah) that can support both Northguard and Kafka. While a Kafka client can only talk to a single Kafka cluster, Xinfra is not bound by the same limitations, allowing an application using Xinfra to simultaneously support Kafka and Northguard. “This means users don’t need to change the topic when it is migrated between clusters at runtime,” the engineers write.
LinkedIn has already migrated thousands of topics from Kafka to Northguard, but it still has several hundred thousand to go. The good news for LinkedIn is that more than 90% of its applications now are running Xinfra clients, which should make the migration easier.
“Looking ahead, our focus will be on driving even greater adoption of Northguard and Xinfra, adding features such as auto-scaling topics based on traffic growth, and enhancing fault tolerance for virtualized topic operations,” the engineers write. “We are thrilled to continue this journey!”
Related Items:
Confluent Says ‘Au Revoir’ to Zookeeper with Launch of Confluent Platform 8.0
LinkedIn Implements New Data Trigger Solution to Reduce Resource Usage For Data Lakes
Leading Solution Providers









Tabor Network













