


May 20, 2025
Fine-Tuning LLM Performance: How Knowledge Graphs Can Help Avoid Missteps

(GarryKillian/Shutterstock)
Fine-tuning is a crucial process in optimizing the performance of pre-trained LLMs. It involves further training the model on a smaller, more specific dataset tailored to a particular task or domain. This process allows the Large Language Model (LLM) to adapt its existing knowledge and capabilities to excel in specific applications such as answering questions, summarizing text, or generating code. Fine-tuning enables the incorporation of domain-specific knowledge and terminology that might not have been adequately covered in the original pre-training data. It can also help align an LLM’s output style and format with specific requirements.
However, traditional fine-tuning methods are not without their limitations. They typically require a substantial amount of high-quality, labeled training data, which can be costly and time-consuming to acquire or create. Even after fine-tuning, the model might still be prone to generating inaccuracies if the training data is not comprehensive enough or if the base model has inherent biases. The fine-tuning process itself can also be computationally intensive, especially for very large models.
Perhaps most importantly, traditional fine-tuning may not effectively instill deep, structured knowledge or robust reasoning abilities within the LLM. For example, supervised fine-tuning involves training on question-answer pairs to optimize performance. While this can improve the model’s ability to answer questions, it may not necessarily enhance its underlying understanding of the subject matter.
Despite its utility in adapting LLMs for specific purposes, traditional fine-tuning often falls short in providing the deep, factual grounding necessary for truly dependable and precise performance in domains that require extensive knowledge. Simply providing more question-answer pairs may not address the fundamental lack of structured knowledge and reasoning capabilities in these models.

(a-image/Shutterstock)
Unlocking Enhanced LLM Fine-tuning through Knowledge Graphs
Leveraging knowledge graphs (KGs) offers a powerful approach to enhance the fine-tuning process for LLMs, effectively addressing many of the limitations associated with traditional methods. By integrating the structured and semantic knowledge from KGs, organizations can create more accurate, reliable, and contextually aware LLMs. Several techniques facilitate this integration.
One significant way knowledge graphs can improve LLM fine-tuning is through the augmentation of training data. KGs can be used to generate high-quality, knowledge-rich datasets that go beyond simple question-answer pairs. A notable example is the KG-SFT (Knowledge Graph-Driven Supervised Fine-Tuning) framework. This framework utilizes knowledge graphs to generate detailed explanations for each question-answer pair in the training data. The core idea behind KG-SFT is that by providing LLMs with these structured explanations during the fine-tuning process, the models can develop a deeper understanding of the underlying knowledge and logic associated with the questions and answers.
The KG-SFT framework typically consists of three main components:
- Extractor which identifies entities in the Q&A pair and retrieves relevant reasoning subgraphs from the KG;
- Generator which uses these subgraphs to create fluent explanations; and
- Detector which ensures the reliability of the generated explanations by identifying potential knowledge conflicts.
This approach offers several benefits, including improved accuracy, particularly in scenarios where labeled training data is scarce, and enhanced knowledge manipulation abilities within the LLM. By providing structured explanations derived from knowledge graphs, fine-tuning can move beyond mere pattern recognition and focus on instilling a genuine understanding of the knowledge and the reasoning behind it. Traditional fine-tuning might teach an LLM the correct answer to a question, but KG-driven methods can help it comprehend why that answer is the correct one by leveraging the structured relationships and semantic information within the knowledge graph.
Incorporating Knowledge Graph Embeddings
Another powerful technique involves incorporating knowledge graph embeddings into the LLM fine-tuning process. Knowledge graph embeddings are vector representations of the entities and relationships within a KG, capturing their semantic meanings in a dense, numerical format. These embeddings can be used to inject the structured knowledge from the graph directly into the LLM during fine-tuning.
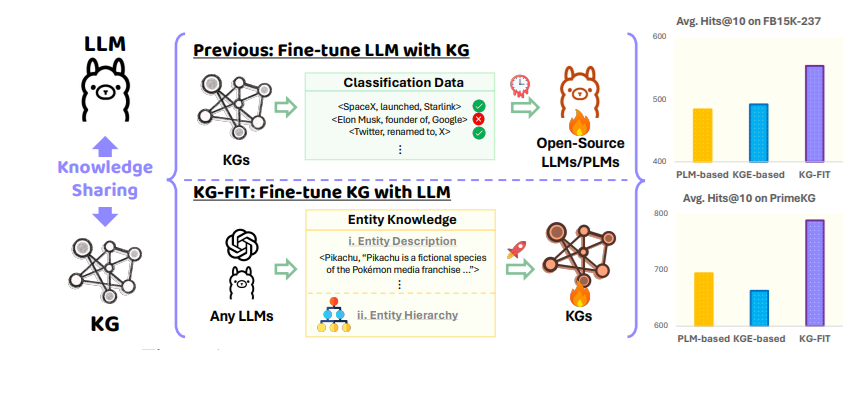
“Fine-tune LLM with KG” vs “Fine-tune KG with LLM (Source: KG-FIT: Knowledge Graph Fine-Tuning Upon Open-World Knowledge)
KG-FIT is an example of this technique. It utilizes LLM-guided refinement to construct a hierarchical structure of entity clusters from the knowledge graph. This hierarchical knowledge, along with textual information, is then incorporated during the fine-tuning of the LLM. This method has the potential to capture both the broad, contextual semantics that LLMs are good at understanding and the more specific, relational semantics that are inherent in knowledge graphs.
By embedding the knowledge from a graph, LLMs can access and utilize relational information in a more efficient and nuanced manner compared to simply processing textual descriptions of that knowledge. These embeddings can capture the intricate semantic connections between entities in a KG in a format that LLMs can readily process and integrate into their internal representations.
Graph-Aligned Language Model (GLaM) Fine-tuning
Frameworks like GLaM (Graph-aligned Language Model) represent another innovative approach to leveraging knowledge graphs for LLM fine-tuning. GLaM works by transforming a knowledge graph into an alternative textual representation that includes labeled question-answer pairs derived from the graph’s structure and content. This transformed data is then used to fine-tune the LLM, effectively grounding the model directly in the knowledge contained within the graph. This direct alignment with graph-based knowledge enhances the LLM’s capacity for reasoning based on the structured relationships present in the KG.
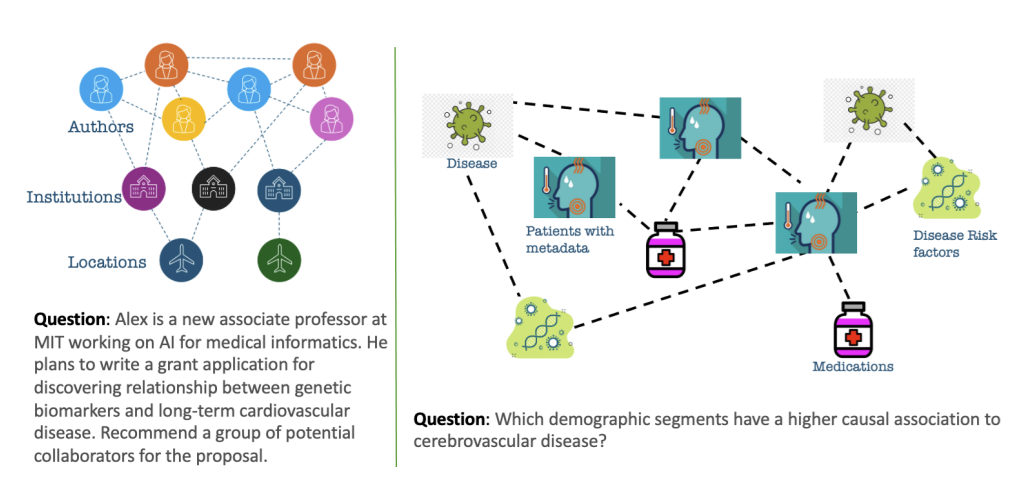
Figure 1: Motivating examples for aligning foundational models with domain-specific knowledge graphs. The left figure demonstrates a query where a LLM needs to be integrated with a knowledge graph derived from a social network. The right figure demonstrates a need where a LLM needs to be integrated with a patient-profiles to disease network extracted from an electronic healthcare records database (Source: GLaM: Fine-Tuning Large Language Models for Domain Knowledge Graph Alignment via Neighborhood Partitioning and Generative Subgraph Encoding)
For certain tasks that heavily rely on structured knowledge, this approach can serve as an efficient alternative to methods based on Retrieval-Augmented Generation (RAG). By directly aligning the LLM with the structure of the knowledge graph during the fine-tuning phase, a deeper integration of knowledge and improved reasoning capabilities can be achieved. Instead of just retrieving information from a KG at the time of inference, this method aims to internalize the graph’s structural information within the LLM’s parameters, allowing it to reason more effectively about the relationships between entities.
Instruction Fine-tuning for Knowledge Graph Interaction
LLMs can also be instruction fine-tuned to improve their ability to interact with knowledge graphs. This involves training the LLM on specific instructions that guide it in tasks such as generating queries in graph query languages like SPARQL or extracting specific pieces of information from a KG. Furthermore, LLMs can be prompted to extract entities and relationships from text, which can then be used to construct knowledge graphs. Fine-tuning the LLM on such tasks can further enhance its understanding of knowledge graph structures and improve the accuracy of information extraction.
After undergoing such fine-tuning, LLMs can be more effectively used to automate the creation of knowledge graphs from unstructured data and to perform more sophisticated queries against existing KGs. This process equips LLMs with the specific skills required to effectively navigate and utilize the structured information contained within knowledge graphs, leading to a more seamless integration between the two.
Attaining Superior LLM Performance and Reliability
The enhanced LLM fine-tuning capabilities enabled by knowledge graphs provide a compelling new reason for organizations to invest in this technology, particularly in the age of GenAI. This approach offers significant benefits that directly address the limitations of both traditional LLMs and traditional fine-tuning methods. Fine-tuning LLMs with knowledge derived from verified knowledge graphs significantly reduces the occurrence of hallucinations and enhances the factual accuracy of their outputs. Knowledge graphs serve as a reliable source of truth, providing LLMs with a foundation of verified facts to ground their responses.
For instance, a knowledge graph can provide real-world, verified facts, allowing AI to retrieve accurate information before generating text, thereby preventing the fabrication of information. In critical applications where accuracy is paramount, such as healthcare, finance, and legal domains, this capability is crucial. By significantly reducing the generation of incorrect information, organizations can deploy LLM-powered solutions in these sensitive areas with greater confidence and trust.
About the Author: Andreas Blumauer is Senior VP Growth, Graphwise the leading Graph AI provider and the newly formed company as the result of the recent merger of Ontotext with Semantic Web Company. To learn more visit https://graphwise.ai/ or follow on Linkedin.
Related Items:
The Future of GenAI: How GraphRAG Enhances LLM Accuracy and Powers Better Decision-Making
Why Young Developers Don’t Get Knowledge Graphs
Applications:
Data Management
Technologies:
Middleware
Sectors:
Biosciences
Vendors:
Graphwise
Tags:
fine-tuning, GenAI, GLaM, graph algorithms, KG-FIT, KG-SFT, knowledge graphs, large language model, LLM
Leading Solution Providers

















