

May 7, 2025
Ambari Hadoop Cluster Manager is Back on the Elephant

The term “Hadoop Cluster” can have many meanings. In the most simple sense, it can refer to the core components: HDFS (Hadoop Distributed FileSystem), YARN (Resource scheduler), Tez, and batch MapReduce (MapReduce processing engines). In reality, it is much more.
Many other Apache big data tools are usually provided and resource-managed by YARN. It is not uncommon to have HBase (Hadoop column-oriented database), Spark (scalable language), Hive (Hadoop RDBS), Sqoop (database to HDFS tool), and Kafka (data pipelines). Some background processes, like Zookeeper, also provide a way to post cluster-wide resource information.
Every service is installed separately with unique configuration settings. Once installed, each service requires a daemon to be run on some or all of the cluster nodes. In addition, each service has its own raft of configuration files that must be kept in sync across the cluster nodes. For even the simplest installations, it is common to have over 100-200 files on a single server.
Once the configuration has been confirmed, start-up dependencies often require specific services to be started before others can work. For instance, HDFS must be started before many of the services will operate.
If this is starting to sound like an administrative nightmare, it is. These actions can be “scripted-up” at the command line level using tools like pdsh (parallel distributed shell). Still, even that approach gets tedious, and it is very unique for each installation.
The Hadoop vendors developed tools to aid in these efforts. Cloudera developed Cloudera Manager, and Hortonworks (now part of Cloudera) created open-source Apache Ambari. These tools provided GUI installation assistance (tool dependencies, configuration, etc.) and GUI monitoring and management interfaces for full clusters. The story gets a bit complicated from this point.
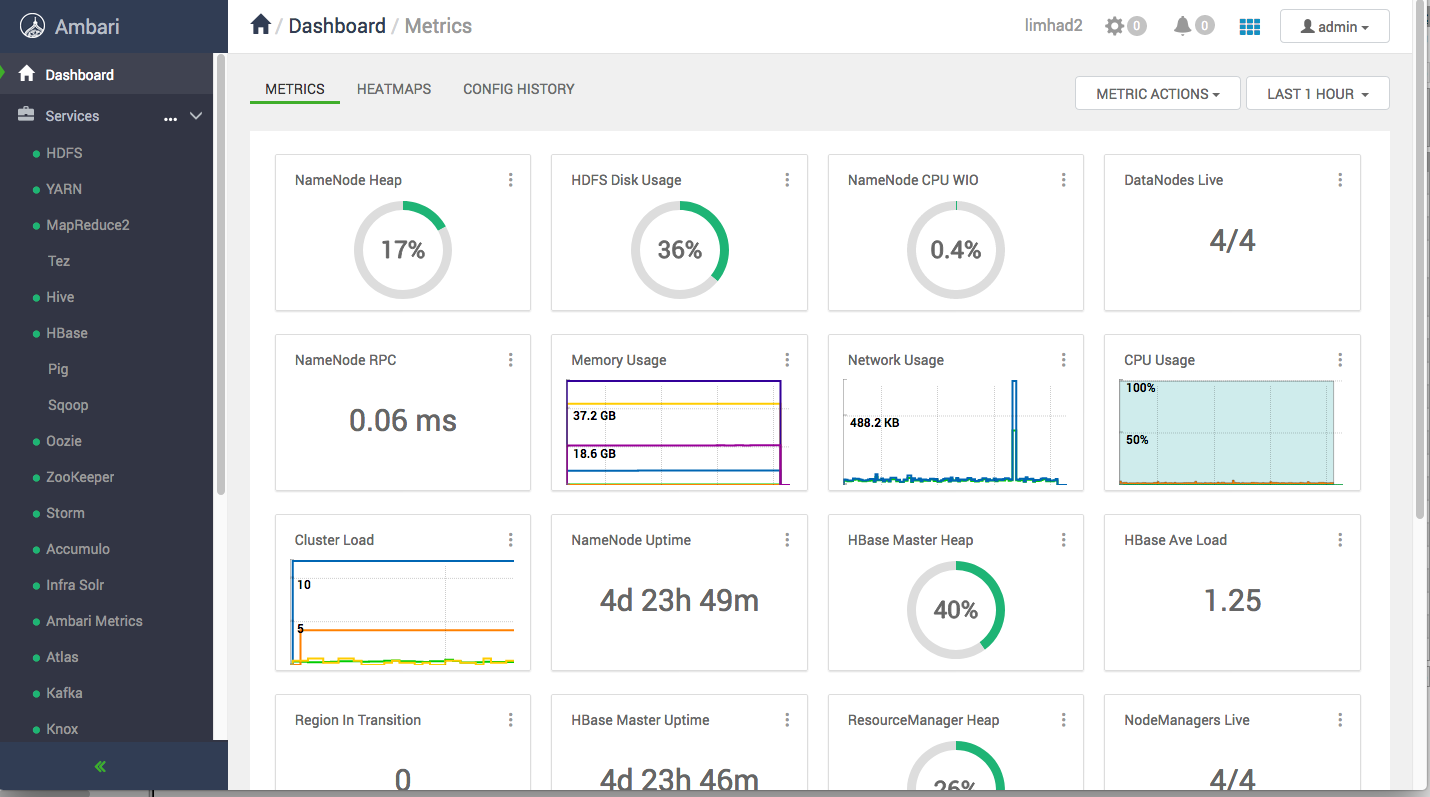
The Ambari Dashboard (Source: Author)
The back story
In the Hadoop world, there were three big players: Cloudera, Hortonworks, and MapR. Of the three, Hortonworks was often called the “Red Hat” of the Hadoop world. Many of their employees were big contributors to the open Apache Hadoop ecosystem. They also provided repositories where RPMs for the various services could be freely downloaded. Collectively, these packages were referred to as Hortonworks Data Platform or HDP.
As a primary author of the Ambari management tool, Hortonworks provided repositories used as an installation source for the cluster. The process requires some knowledge of your needs and Hadoop cluster configuration, but in general Ambari is very efficient in creating and managing an open Hadoop cluster (on-prem or in the cloud).
In the first part of 2019, Cloudera and Hortonworks merged. Around the same time, HPE purchased MapR.
Sometime in 2021, public access to HDP updates after version 3.1.4 was shut down, making HDP effectively closed source and requiring a paid subscription from Cloudera. One could still download these packages from the Apache website, but not in a form that could be used by Ambari.
Much to the dismay of many administrators, this restriction created an orphan ecosystem of open-source Ambari-based clusters and effectively froze these systems at HDP version 3.1.4.
The way forward
In April this year, the Ambari team released version 3.0.0 (release notes) with the following important news.
Apache Ambari 3.0.0 represents a significant milestone in the project’s development, bringing major improvements to cluster management capabilities, user experience, and platform support.
The biggest change is that Ambari now uses Apache Bigtop as its default packaging system. This means a more sustainable and community-driven approach to package management. If you’re a developer working with Hadoop components, this is going to make your life much easier!
The shift to Apache Bigtop removes the limitation of the Cloudera HDP subscription wall. The release notes also state, “The 2.7.x series has reached End-of-Life (EOL) and will no longer be maintained, as we no longer have access to the HDP packaging source code.” This choice makes sense because Cloudera ceased mainstream and limited support for HDP 3.1 on June 2, 2022.
The most recent release of BigTop (3.3.0) includes the following components that should be installable and manageable through Ambari.
- alluxio 2.9.3
- bigtop-groovy 2.5.4
- bigtop-jsvc 1.2.4
- bigtop-select 3.3.0
- bigtop-utils 3.3.0
- flink 1.16.2
- hadoop 3.3.6
- hbase 2.4.17
- hive 3.1.3
- kafka 2.8.2
- livy 0.8.0
- phoenix 5.1.3
- ranger 2.4.0
- solr 8.11.2
- spark 3.3.4
- tez 0.10.2
- zeppelin 0.11.0
- zookeeper 3.7.2
The release notes for Ambari also mention these additional services and components
- Alluxio Support: Added support for Alluxio distributed file system
- Ozone Support: Added Ozone as a file system service
- Livy Support: Added Livy as an individual service to the Ambari Bigtop Stack
- Ranger KMS Support: Added Ranger KMS support
- Ambari Infra Support: Added support for Ambari Infra in Ambari Server Bigtop Stack
- YARN Timeline Service V2: Added YARN Timeline Service V2 and Registrydns support
- DFSRouter Support: Added DFSRouter via ‘Actions Button’ in HDFS summary page
The release notes also provide this compatibility matrix, which covers a wide range of operating systems and the main processor architectures.

Ambari compatibility matrix (Source: Ambari release notes)
Back on the elephant
Now that Ambari is back on track, help managing open Hadoop ecosystem clusters can continue. Ambari’s installation and provisioning component manages all needed dependencies and creates a configuration based on the specific package selection. When running Apache big data clusters, there is a lot of information to manage, and tools like Ambari help administrators avoid many issues found in the complex interaction of tools, file systems, and workflow.
Finally, a special mention is in order to the Ambari community for the large amount required for this new release.
Applications:
Data Management
Sectors:
Academia, Biosciences, Energy, Financial Services, Government, Healthcare, Manufacturing, Retail, Science, Telecommunications
Leading Solution Providers









Tabor Network
















