


May 14, 2024
Forrester Slices and Dices the Vector Database Market

(Andy Chipus/Shutterstock)
The large language model (LLM) revolution has transformed vector databases from obscure search tech into must-have products for AI success. But which vector database features should you look for, and which vendors are innovating? The analysts at Forrester recently dug into the field to provide answers in a new report.
Vector databases are designed to manage and process one particular data type called a vector embedding, which is a numerical representation of words, documents, images, or even sound. A vector database indexes and stores these embeddings in a multi-dimensional space that allows users or applications to retrieve these embeddings and others nearby that they resemble. This similarity search function is what enabled users to get much better search results than straightforward keyword-matching, and led to the creation of so-called “AI search engines.”
When ChatGPT dropped the LLM bomb on the world in late 2022, a new use for vector databases was quickly discovered. By storing a set of source documents as embeddings in a vector database and then calling on the database to serve information from those documents via similarity search conducted at runtime as part of the prompt engineering or retrieval-augmented generation (RAG) process, GenAI users discovered they could greatly improve the quality of the responses generated by chatbots, co-pilots, and other forms of AI interactions enabled by LLMs like ChatGPT.
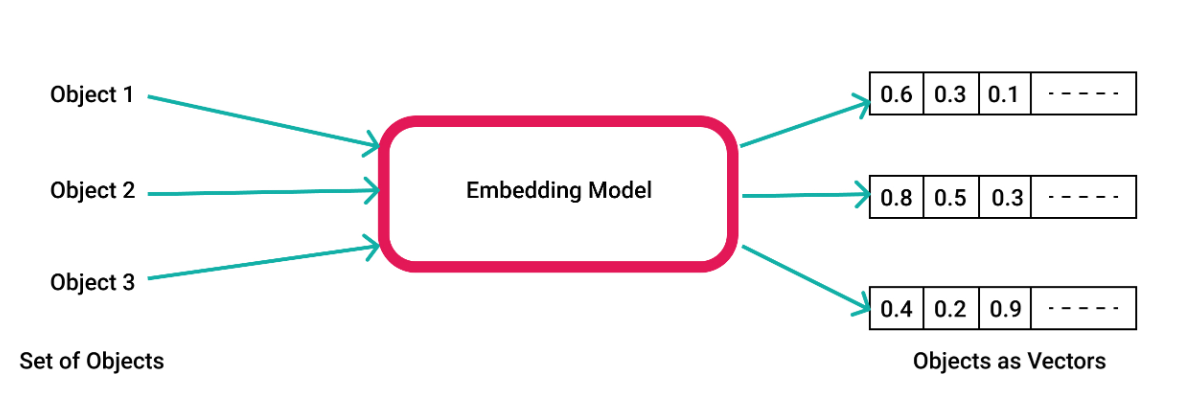
Vector embeddings are numerical representations of an object (Rajat Tripathi/Pinecone)
Just a few “native” vector databases existed prior to ChatGPT, such as Pinecone, Milvus, and
Zilliz. But almost overnight, many existing database vendors adapted their wares to be able to store, index, and process vector data, too, including Elastic, DataStax, Couchbase, MongoDB, and even Teradata. For NoSQL and relational databases that were already multi-modal in nature, the addition of the vector data type was a no-brainer.
However, as the market for vector databases exploded, it also created some confusion among users about what is the best approach to adopting vector databases. “Is the pgvector plug-in for Postgres sufficient for my GenAI needs? What benefits does a native vector database bring that multi-modal databases can’t match? Do these vector databases only run in the cloud or can I run them on-prem too?”
Enter Forrester, the longtime IT analyst group based in Cambridge, Massachusetts. In “Vector Databases Landscape, Q2 2024” report, Forrester analyst Noel Yuhanna and several of his colleagues dug into the burgeoning market for vector databases while slicing and dicing the vector database capabilities from 24 vendors.

Vector databases provide access to indexed vector embeddings in a multi-dimensional search space
Forrester started out by defining its terms. “A database management system that provides storage, indexing, processing, and access for data represented by vectors to support similarity searches, RAG apps, modern generative AI/LLM apps, and vector-based analytics,” the company states.
“Customers leverage vector databases to support customer experiences, RAG applications, image similarity search, real-time anomaly data detection, optimized recommendation engines, and fraud detection,” it continues. “Despite being in the nascent stages of this market, we anticipate a surge in diverse use cases in the near term.”
Forrester sees the market for vector database divided into two main segments: native vector DBs and multi-modal vector DBs.
The key difference between the camps, Forrester says, is the greater scalability of native vector DBs, “particularly when handling large volumes of vectors.” The main advantage of a multimodal vector DB, meanwhile, is that it can store other types of data, potentially eliminating the need for two or more separate databases.
The challenges of scale in vector databases have not been entirely solved, and the high-end “is still a work in progress,” Forrester says. “High-end scale and performance still require considerable effort, especially when supporting tens of billions of data points (vectors).”

Source: Forrester report “Vector Databases Landscape, Q2 2024”
Forrester didn’t rank the vector databases by their capabilities to tackle standard vector database duties (perhaps that will be the subject of an upcoming Forrester Wave). But it did look into which databases are being positioned for some of the emerging use cases for vector databases, which is handy to know (see image to the right).
The market for vector databases has seen a large number of entrants over the past 12 months, which makes for interesting dynamics that observers and customers should closely watch, Forrester says.
For instance, the capabilities expected of vector databases is changing. Core functions, like vector storage, indexing, and processing, are being augmented with more advanced features, “including enhanced security measures, optimized processing capabilities, and seamless integration with diverse vector embedding transformers and data streaming engines,” the analyst group says.
Another thing to look out for is market bleed-over. Cloud data platforms, including data fabrics and data lakehouses, are also adopting vector capabilities, Forrester says, which could further disrupt the market for vector databases.
“This trend underscores a shift toward comprehensive data management solutions that seamlessly integrate vector functionality, potentially reshaping the landscape of specialized vector databases,” Yuhanna and the Forrester analysts write.
Related Items:
Vector Databases Emerge to Fill Critical Role in AI
Home Depot Finds DIY Success with Vector Search
Can Thought Vectors Deliver Human-Level Reasoning?
Applications:
Data Management
Sectors:
Retail
Leading Solution Providers
















