


September 23, 2022
Has Macrometa Cracked the Code for Global, Real-Time Data?

(Zia-Liu/Shutterstock)
There are plenty of organizations trying to solve one tough problem: How do you combine real-time and historical data in a distributed context, and trust the results of your queries? Plenty of companies have tried to solve it by combining mostly open source technologies, with various levels of success. But now a startup called Macrometa claims it has cracked the problem with a proprietary data network delivered, Akamai-style, via 175 data centers.
The junction of historical and real-time data is a lucrative place for modern applications, but it continues to challenge technologists and modern technologies.
For example, Google addresses it from a global transactional context by using expensive atomic clocks in its data center to track the order of new events flowing into its Spanner database, while others replicate that approach with complex protocols.
Some follow the Lambda architecture, which basically melds a traditional database designed to maintain state with a pub/sub system like Apache Kafka that’s designed to manage event data.
These approaches can work, but they all have various drawbacks and dilemmas that are preventing application developers from getting the full value out of their data, according to Chetan Venkatesh, a distributed database veteran and cofounder and CEO of Macrometa.

(Peshkova/Shutterstock)
“Almost all our customers are folks who have tried to cobble this together and failed, and essentially ended up replacing it with us,” Venkatesh says.
One of those customers was Cox Communications. The company wanted to build a system to ingest events that would feed real-time applications. The applications demanded low-latency data, but the cloud provider that Cox chose for the project couldn’t deliver the goods, Venkatesh says.
“What they found was, for the amount of data they were sending in, the scale at which they had to build and integrate these systems was too complex, too slow, and that gave them a picture of their data that was minutes, if not hours, beyond reality,” Venkatesh tells Datanami. “And so they brought us in, and we were able to shave the cost off by 90%, but give them a picture of reality that’s in the hundreds of milliseconds of latency.”
Big, Fast Data
How Venkatesh and his co-founder chose to architect Macrometa says a lot about the tradeoffs companies are facing at the junction of big and fast data.
It would be nice if there was an open source technology that could solve this problem. But it doesn’t exist, Venkatesh says. So in the time-honored of technologists everywhere, they decided to build it themselves.
Macrometa has taken a novel, mostly proprietary approach to this problem that combines existing design patterns in a new and potentially valuable way. It starts with the idea of a global data mesh, and it ends with a kind of new operational data platform, Venkatesh says.![]()
“It extends the idea of a data mesh. Instead of a data mesh being a centralized resource, it’s a distributed resource,” he says. “We’re taking the data mesh, breaking it apart, and bundling it and making it available in 175 locations around the world, roughly 50 milliseconds away from 90% of devices in the world that can act on the Internet, and now provide new real-time layer for application developers to be able to build these exciting new applications.”
Macrometa builds on the core data mesh concepts laid down by Zhamak Dehghani, but extends it into the direction of real-time applications, he says.
“It takes many of those data mesh principles that she first talked about, but really brings it into world of real time with very fast moving amounts of what I call big and fast data,” he says. “So it’s at that intersection of big, fast data and the need for data to be global rather than centralized in one location, far, far away from where users, devices, and systems need them.”
Building these types of applications requires a lot of the digital equivalent of glue and bailing wire, and it’s fragile to run, Venkatesh says. “Our vision was provide one simple API that does all those things very, very quickly, and in real time for end users and developers.”
Conflict-Free Replicated Data Types
The technologies that Macrometa built to construct this system are mostly proprietary, with the exception of the RocksDB storage engine, which is the same storage engine that Confluent uses with ksqlDB, and Badger.io, a lightweight version of RocksDB. Macrometa developed the mostly proprietary system in order to handle future data volumes, which will likely be in the trillions of events per second.
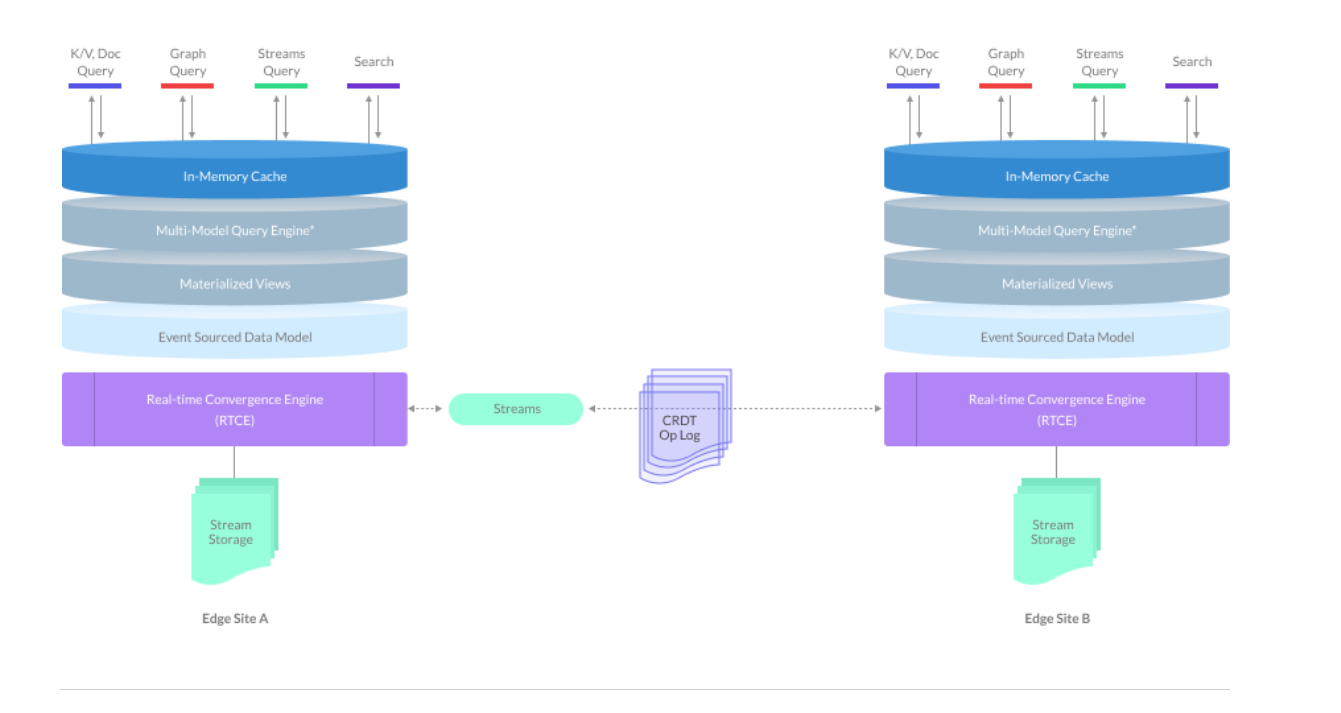
Macrometa architecture
“What does the world look like when you’re having to ingest potentially trillions of events per second?” Venkatesh asks. “Most of these systems, their legacy is centralized databases and data structure that come from a pre-cloud era. And so the scale at which you ingest and process data, it’s very expensive to do it at those scales, trillions per second. So we started with a completely new database model and map.”
The key technological breakthrough came in the form of a new approach called causal data consistency, which is driven by a technique dubbed conflict-free replicated data types, or CRDTs. Macrometa didn’t come up with the CRDT concept–that credit goes to a computer scientist named Marc Shapiro, who devised them about a decade ago. Macrometa’s contribution is to bring CRDTs to the mainstream world of JSON.
“Our real value is the fact that we generalized it to all the different JSON data types and built a database and a data engine on top of it,” he says. “We use those the core foundational primitives in our system and built a completely new event ingestion engine based on that, that can ingest events at a fraction of the cost of Kafka but at 100x the velocity that Kafka can.”
Macrometa’s secret sauce is how it transforms all data changes into a CRDT operation, which is then replicated to all the Macrometa locations using a vector clock, as opposed to timestamps used in other globally consistent databases like Google Cloud Spanner or CockroachDB.

Macrometa CEO and cofounder Chetan Venkatesh
“Using the vector clock and a causal tree of changes, we can essentially serialize and get these serialization ACID-like guarantees, so [we can get] the consistency of the system without actually needing to exchange a lot of messages with all these different applications,” Venkatesh says.
The challenge with other approaches is that they introduce a centralized arbitration layer, he says. Any data mutations have to go through that arbitration layer. “And the minute you have that, the number of participants that are connected to that arbitration layer become the constraining factor in how big that cluster or that network can become,” he says.
Current distributed systems can handle four or five nodes in a globally distributed network before the collected weight of the internal messaging becomes too much for the cluster to bear. “You can get relatively decent performance with four to five locations around the world,” he says. “But add a sixth location, and your throughput and transactions drop by 50%. Add a seventh location and it’s 90% down. Now it’s no longer useful.”
The community initially was skeptical of the CRDT approach. But as the company demonstrated its technology and worked with universities to validate the research, those suspicions fell away. The company has published a research paper that includes formal proofs for the approach, which has also helped to quiet the doubters, Venkatesh says.
Three-Layered Data Cake
Conceptually, Macrometa has three layers: a data fabric to move the data, a compute layer to process the data, and a data governance layer to ensure customers are not violating data privacy and data sovereignty laws.
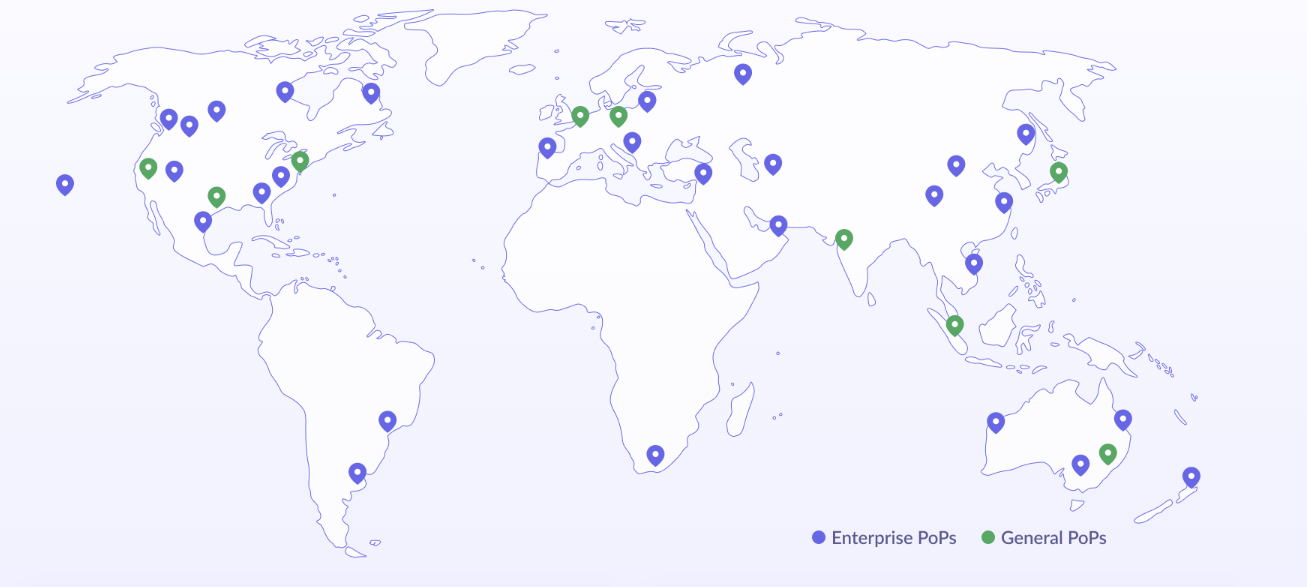
Macrometa point of presence (POP) sites
From an architectural point of view, there are also three main pieces (three is the magic number, of course).
At the core is a shapeshifting NoSQL data platform that can function as a key-value store, a document store, a graph database, a streaming database, or a time-series database. The database speaks standard Postgres SQL, with some extensions for the non-relational stuff.
“In our platform, streams and tables are the same things,” he says. “It’s just that streams are real time user tables. And so you can interact with your data in both real time, in-motion fashion with streams, via pub/sub, or you can query it using request-response with SQL.”
Next to the NoSQL data store is a compute engine that allows developers to build functions and commands. “They can essentially model their data interactions as functions, and we can deploy that, and it runs in-situ with the data across our data network in all these locations,” Venkatesh says.
At the end of the day, the Macrometa platform essentially deliver a full database, a pub/sub system like Kafka, and a complex event processing system like Flink, along with compute engine so you can build a real-time data application, completely distributed using us” via the 175-site CDN.
There is no open source (save for a sprinkling of RocksDB) “because we have to have very tight control over all these layers to be able to give you these strong, deterministic guarantees on latency, performance, and location,” Venkatesh says.
“The storage engine is a very small but integral part of our stack,” he says. “The real value is in the approach we have for the way we ingest data into the log, the way we collapse that log into objects in real time, and most importantly, the way we can replicate that data across hundreds of locations with transactional and consistency guarantees. That’s always been the missing piece.”
The Macrometa offering has been available for two years, and the company has around 70 paying customers, including Verizon and Cox Communications. In fact, Cox Communications has become a partner of Macrometa and is offering the company’s technology via its data centers, Venkatesh says. The company has raised $40 million, and will be raising more soon.
Related Items:
Is Real-Time Streaming Finally Taking Off?
7 Reference Architectures for Real-Time Analytics
Leading Solution Providers

















