


July 21, 2022
Speedb Picks Up Where RocksDB Leaves Off

Enterprise metadata management (EMM) tools are fast becoming a necessity in this new age when companies are drowning in a flood of metadata. NoSQL databases are a popular alternative to their relational database counterparts for many use cases, including EMM.
The most basic type of NoSQL database is the key-value store, a database composed of a key and an associated data value (which can be a number, a string, or even another set of key-value pairs). A key-value store’s simple structure has speed and performance advantages for certain use cases where horizontal scaling is needed, such as serving queries on read-only data on large websites with heavy traffic.
A popular embedded key-value store is RocksDB, an open source project with a large community of contributors created in 2012. Now there’s a new key-value player in town: Speedb. The company bills its data storage engine as a drop-in replacement for RocksDB.
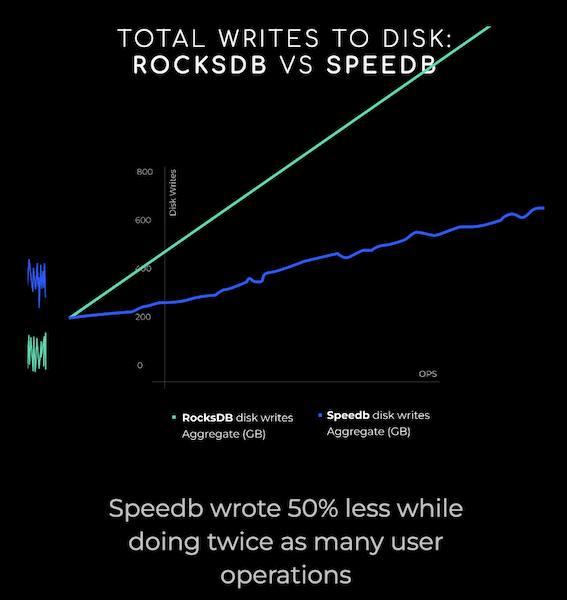
According to Speedbd, not all key-value stores are created equal in terms of performance and scale, especially for managing today’s growing volumes of metadata that are increasingly important for business operations. Speedb lists some of the problems RocksDB users have faced, including I/O hangs and stalls, code instability, database size limitations, excessive tuning, sharding, and write amplification.

A still from an introductory video shows the capabilities of Speedb. Source: Speedb
Adi Gelvan, Speedb co-founder and CEO, was working for Infinidat where he needed an EMM solution that did not involve beefing up system hardware or restructuring his entire existing data stack. He landed on RocksDB but quickly realized that it would not be scalable past 100GB. It was suggested he would need to shard RocksDB by breaking down his datasets into more manageable chunks and assigning each one to its own node with its own storage engine, but Gelvan was not thrilled with the idea of the extra work and complexity that would entail.
It was then, in Nov. 2020, that Gelvan and his co-founders decided to build their own data engine that was hyper-scalable, high-performance and used less computing power, and Speedb was born.
RocksDB is organized as a log-structured merge (LSM) tree, a structure that maintains the key-value pairs needed in a key-value store. For their engine, Gelvan and his colleagues re-implemented and improved upon the LSM tree structure to increase its efficiency while making sure it was compatible with the RocksDB API in order to appeal to current RocksDB users. The co-founders claim their engine can process 100x more data, at 10x the speed, using 80% fewer resources than RocksDB.
Speedb’s website explains how it works: “The Speedb Data Engine is based on a revolutionary compaction method that reduces the write amplification factor (WAF) from ~30 to ~5. As a result, Speedb eliminates processing latency issues and throughput drops, which are frequently encountered when using traditional LSM-trees, while significantly reducing CPU utilization and memory consumption.
![]() “By redesigning the RocksDB I/O and job schedulers we were able to further improve performance stability and reduce stalls. We have also redesigned RocksDB’s flow control mechanism to eliminate spikes in user latency. Based on these technological breakthroughs, Speedb supports unprecedently fast writes even on large datasets while keeping a B-Tree like read performance.”
“By redesigning the RocksDB I/O and job schedulers we were able to further improve performance stability and reduce stalls. We have also redesigned RocksDB’s flow control mechanism to eliminate spikes in user latency. Based on these technological breakthroughs, Speedb supports unprecedently fast writes even on large datasets while keeping a B-Tree like read performance.”
The engine also features a probabilistic index that uses a hierarchical data map and consumes less than 3 bytes per object, regardless of its size. Indexes for large datasets can be stored in DRAM which allows for mapping hundreds of billions of objects with only one media access per read. For enterprise users, Speedb is optimized with real-time monitoring, adaptive auto-tuning of system parameters, advanced reporting capabilities, and enterprise-grade support and customization for specific use-cases.
Among Speedb’s first business partners is Redis, an in-memory data structure store with offices in the same Tel Aviv building where Gelvan developed Speedb. In December 2021, about a month after the Speedb engine’s official launch, the company announced a $4 million funding round and the Redis partnership. As the storage engine for the Redis on Flash database, Speedb says Redis on Flash users can double their throughput and capacity while reducing latency, driving up performance, and reducing costs.
Source: Speedb
This week, Speedb revealed that hybrid cloud security firm XM Cyber has adopted Speedb to improve its Attack Path Management platform, a product that “lets customers continuously see their on-premises and cloud networks through the eyes of an attacker, and spot attacks before they happen.” The platform provides simulations of attack paths and uses Apache Flink (which uses RocksDB) for data operations. As the company’s metadata grew, RocksDB slowed it all down with memory bottlenecks and performance degradation, but now, Speedb has provided between 8.7 and 10.2x greater performance for the platform.
“I’ve rarely seen such a fast, elegant and simple solution to a deep-tech challenge as we experienced with Speedb,” said Yaron Shani, senior researcher and technology lead at XM Cyber. “Speedb’s impact was instantaneous, after simply replacing a few lines in the Docker files. Its dramatic improvement in memory utilization and performance allows us to give our customers better products and services than ever before. During the process of working together, we even discovered unique problems we were unaware of. Speedb is now deployed in our main build that goes to all customers, large and small.”
To learn more about the Speedb data engine, visit this link.
Related Items:
Five Emerging Trends in Enterprise Data Management
There’s a NoSQL Database for That
The Future of Data Management: It’s Already Here
Vendors:
Speedb
Leading Solution Providers
















