


June 9, 2015
MapR Targets Hadoop’s Batch Constraints with 5.0
Hadoop has been largely batch-oriented up to this point, but that’s changing as companies figure out how to exploit big data for competitive advantage. One vendor that’s looking to accelerate the change is MapR Technologies, which today at the Hadoop Summit unveiled a major update of its distribution aimed at helping companies use various Hadoop engines to make good decisions against fast-moving data.
When it comes to Hadoop distributors, MapR Technologies stands apart from other Hadoop distributors due to the modifications it’s made to Apache Hadoop and its willingness to venture off the open source track. Whereas HDFS was built to be a write-once, read-many system that uses data appends to handle updates to files, MapR decided that Hadoop should have sequential file processing, so it built NFS into the mix. Then it decided Hadoop applications should have random read-write capabilities, so it added an integrated NoSQL database dubbed MapR-DB.
The MapR-DB was outfitted with a table synchronization functionality earlier this year in version 4.1 that automatically replicated data among multiple instances of the NoSQL database. This feature, which MapR dubs its “Real-Time, Reliable Data Transport,” allows customers running multiple MapR-DBs (say for different departments or geographic locations) to count on having the same data available to applications or analytic engines.
With today’s launch of MapR 5.0, the company is extending that same data replication transport mechanism to the Elasticsearch search engine, thereby enabling search indexes to be updated automatically when new data arrives into the MapR platform.
According to MapR’s Chief Marketing Officer Jack Norris, this will make it easier for big data developers to build real-time applications without getting bogged down in writing code. “We’ve taken it up closer to the application level….so you as a developer don’t have to figure out how to do a batch upload to keep a search index updated,” he says.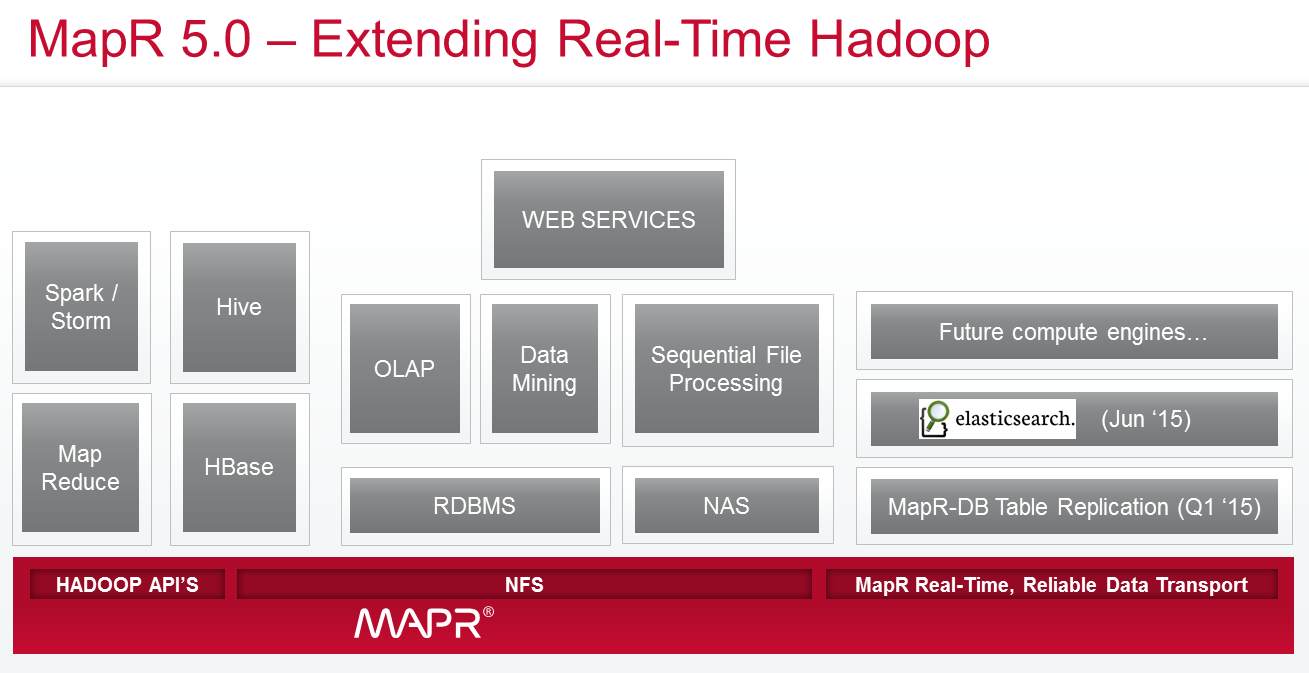
Nearly 20 percent of MapR customers are running more than 50 separate applications on a single cluster, the company says. While diversity of applications and engines is a sign of life in Hadoop, it can also lead to problems when you’re trying to act on that data, Norris says. “You can get different answers and different states based on when something has been appended and when something has been uploaded,” he says. “It’s hard to keep applications in synch.”
That shouldn’t happen in the real-time big data world that MapR envisions. By ensuring that different Hadoop engines have access to the same data as it arrives, it eliminates the need for the developer to worry about data relocations issues, and essentially eliminates the batch constraints, Norris says.
“We’re moving to a new era–away from separate data silos based on the application and analytics type to more of an integrated platform,” Norris says. “When we talk about real time, it’s not that you get very fast query response on data that’s a week old as part of backward-looking reporting function. It’s about impacting business as it happens so you can affect the business results, not just simply report on them.”
Norris says the new features are the result of requirements by MapR customers who want to combine streaming analytics on fast data with large-scale machine learning on big data, and make it available to applications through an operational database that supports random retrieval of different information.
“Say I want to look at a pattern across a year’s worth of data, and if I see the pattern in streaming analytics, I want to send an alert, and when an alert goes out I want to retrieve more information about that from tables,” he says. “To have all of those capabilities integrated to the same platform makes a lot of sense.”
Currently, MapR is supporting replication across MapR-DB, the NFS file system, and Elasticsearch, but more Hadoop-resident processing engines will be added in the future, he says.
MapR 5.0 brings several other changes, including updates to the core Hadoop stack itself. Hadoop and YARN version 2.7 will ship with MapR 5.0. It also brings support for Spark 1.3 (including the new data frames feature); support for application rolling upgrades; and integrated support for Docker containers. See the graphic to the left for more details on MapR 5.0.
Elsewhere on the Hadoop deployment front, MapR also announced its new MapR Auto-Provisioning Templates. These templates are aimed at taking the pain out of Hadoop deployments by automatically getting a Hadoop cluster up and running for the customer. The company will support several pre-built configurations, including Data Lake, which includes common Hadoop services like YARN, Spark, MapReduce, and Hive; a Data Exploration config that supports Apache Drill for interactive SQL analytics; and Operational Analytics, which includes the MapR-DB. All that’s required of the templates is a pre-configured operating to run on, either on-premise or the cloud; they don’t deploy to bare metal.
Lastly, MapR is making some noise on the security front. As big data accumulates in customer sites, the need to secure it becomes a non-trivial task. Every report of a new data breach is a stark reminder that enterprise companies must take big data security seriously.
With MapR 5.0, the company has added new auditing features. All data-access and administrative events occurring in the system are immediately logged as JSON files, the company says. The company is positioning Apache Drill (of which it’s a big backer) as an easy and intuitive way to query those files.
MapR also used the Hadoop Summit to showcase how its partners are helping to build secure big data solutions on its Hadoop platform. It named Centrify, Dataguise, HP’s Security Voltage, Informatica, Protegrity, Syncsort, Talend, Teradata, Waterline Data and Zaloni as key providers of security and data governance solutions for MapR customers.
Related Items:
MapR Delivers Bi-Directional Replication with Distro Refresh
MapR Claims Momentum as Hadoop Subs Grow
Moving Beyond ‘Traditional’ Hadoop: What Comes Next?
Technologies:
Frameworks
Vendors:
MapR Technologies
Leading Solution Providers

















