

January 22, 2013
A Meta-Analysis of MetaData
Meta-fiction and meta-commentary exist as self-referential forms of the larger topic as a whole. When a scandal breaks in the sports world, for example, most journalists will report on and analyze the events while a few will embark on meta-journalism and discuss how the scandal reflects how the world reports on things.
 While these forms can be interesting ways in forming what is relevant in narrative versus what is not, they are relatively uncommon. Metadata, on the other hand, is not uncommon in technology—it exists everywhere. For example, the computer upon which this article is being written is compiling metadata, such as the word document’s time of creation (a meta-reference). And yet, the subject of metadata is somewhat underrated in the context of big data. Embarcadero’s Director of Product Management Henry Olson discussed with Datanami the issues of metadata efficiency and outlined the company’s top-down approach to help alleviate those issues.
While these forms can be interesting ways in forming what is relevant in narrative versus what is not, they are relatively uncommon. Metadata, on the other hand, is not uncommon in technology—it exists everywhere. For example, the computer upon which this article is being written is compiling metadata, such as the word document’s time of creation (a meta-reference). And yet, the subject of metadata is somewhat underrated in the context of big data. Embarcadero’s Director of Product Management Henry Olson discussed with Datanami the issues of metadata efficiency and outlined the company’s top-down approach to help alleviate those issues.
“A lot of organizations have invested in [metadata] governance and have gotten shelfware out of it. Many others don’t know where to start,” Olson said of the problems companies have today in efficiently handling their metadata. “Our approach is to work with our customers to build an enterprise information map.”
Someone who wants to index the entire archive of Twitter such that researchers can efficiently and effectively search the archive (like the Library of Congress is doing) has to deal with (and ultimately rely on) the metadata. While the text in a given tweet may be useful to provide one variable, a second or third variable will likely come from one of the 50 metadata fields attached to a given tweet, with tweet time and location being common examples of those fields.
The fields most likely to be of use to historical researchers are that of time and location. A large scale retailer looking through social media data for insights may also latch onto other fields, such as a user’s interests and followers along with time and location, to properly personalize upcoming marketing pushes and evaluate existing campaigns.
Finding the relevant information by using the underlying metadata as a guide, especially in the context of large organizations with several databases, is one of the larger problems Embarcadero is working on, according to Olson. “In large organizations, we’ve found that there’s an enormous amount of metadata, let alone data, and metadata volumes get pretty vast. So we are continually looking to improve the selectivity of our search algorithm so that when somebody is searching on a business concept, they tend to quickly find what is most relevant.”
The key is to identify which processes are what Olson calls “business-critical”—something for which large organizations with big data requirements already have a decent idea. This top-down concept identifies and organizes the oft-used and most essential of the data sources, from which point Embarcadero goes to work. “This approach focuses on what is going to be most critical in terms of revenue, cost, and risk profile. Those are the processes that we’re most interested in.”
“The critical thing about the top-down approach is that at the end of the day, it’s the processors and the performance of the processors that dictates the business outcome,” said Olson.
Their approach is to provide the underlying architecture between the information storage, management units and the governance units that determine notable metrics, as noted in the image below.
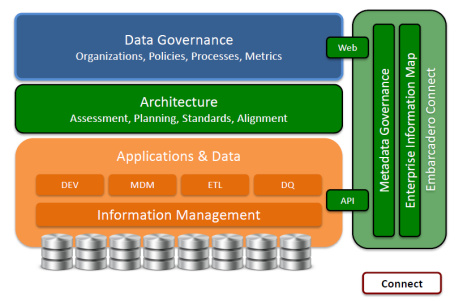
The next step is to discover which databases contain the critical information and, more importantly, which can be left undocumented and unorganized. To explore this aspect, Olson discussed a situation where a company needed to determine efficient distribution methods.
“If you’re searching in an analytic context, you need to get at that production data or its representation in the data warehouse. We can quickly eliminate lots and lots of those databases that are associated with the CRM system or the logistic system or other systems and focus on the ones that have value in the context of a particular search.”
According to Olson, Embarcadero asks which business processes are most critical and moves from there. Taking a bottom-up approach to metadata would be akin to making thousands of barrels, each containing one possible ice cream flavor, before opening an ice cream shop in which only about ten are requested with any regularity.
“A lot of times when organizations deal with enterprise architectural governance initiatives, they get so lost in the forest. They’d be taking along detailed documentation of every database and attribute as an organization.” In this sense, Embarcadero’s mission is to lower the ice cream maker’s scope such that he can make the most efficient use of his production time to fit his clientele.
However, limiting scope of the metadata at which one is looking may eschew some important fields. With that being said, this approach fits the current climate where storage ability outstrips processing power.
“By starting from the standpoint of the most critical business processes, we automatically exercise scope control, leading to a more pragmatic approach. If we were to tell our customers that step one is to document every database in their organization, it’d be a non-starter.” The monetary and time costs, Olson argues, would not be worth the ensuing efficiency kick.
Olson noted that some companies have developed their own systems with the same “breadth and depth” as that of Embarcadero’s. However, Olson argued that those systems are mostly self-serving and geared toward their own products. “There are a few others that have that breadth and depth, but most of them are focused on their particular product line,” said Olson. “For example, Microsoft probably covers all of these steps but they’re very focused on Microsoft technologies. We’re Switzerland, we have a history of working with all of the leading database products and the ability to deliver information to variety of different places.”
Related Articles
Building the Library of Twitter
Greenplum, Kaggle Team to Prospect Data Scientists
IEEE Tags Top Tech Trends of 2013
Leading Solution Providers

















